Zerto Cloud Service Provider’s are the group of people who leverage Zerto Virtual Replication to provide disaster recovery as a service to customers who do not wish to own a DR site. Essentially they (the service provider) have all of the needed infrastructure in place to allow customers to fail over their virtual machines into that service providers environment. So what does it take to be a Zerto cloud service provider?
This article is the second in a series and will describe each of the different major components of Zerto and what they do.
Overview
In the first part of this series I talked, at a high level, about the general architecture of a ZCSP (Zerto Cloud Service Provider). In this part, we will focus on the Zerto components of the solution. Many of the components that ZCSP’s use are the same as those utilized by a regular customer, with a few extra’s added in to make things multi-tenant.
As a quick review, here is what a regular Zerto customer would have installed.
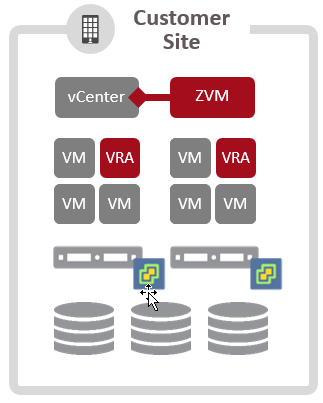
And here is what a ZCSP would have installed.
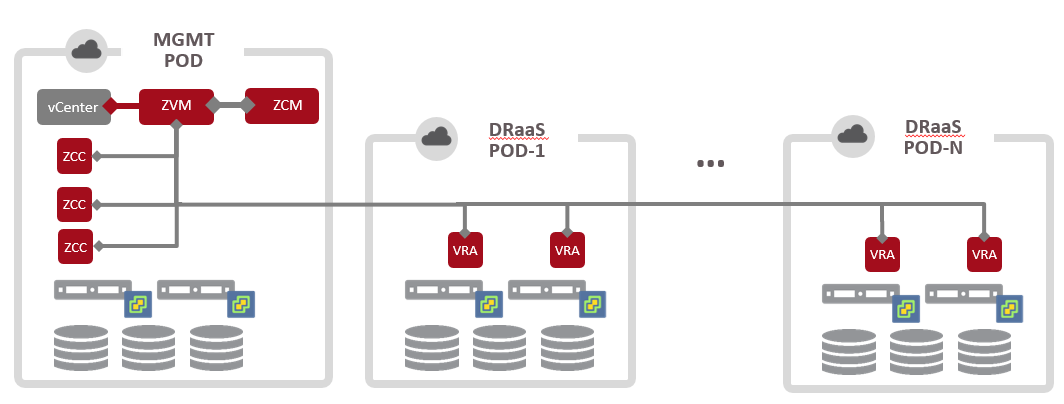
As you can see most of the components of the Zerto solution are reused in a cloud provider environment. In addition to those, there is also a ZCM, ZCC’s, and ZSSP (not show in the diagram). Let’s explain what all of these components are and what they do. Then we can talk about how replication traffic flows between these components.
Zerto Components
ZVM – Zerto Virtual Manager
I like to call the Zerto Virtual Manager the queen bee. She is the management interface for Zerto and in many cases is the only component that most end users ever see.
ZVM is the first component that is deployed for Zerto as well. So it all starts with a single ZVM. From there, pair with your virtualization platform (vCenter), deploy VRA’s and do all of your creation, monitoring, and testing of Virtual Protection Groups.
[stextbox id=”info”]VPG or Virtual Protection Groups are a management mechanism for Zerto to group individual VM’s together. This allows Zerto to keep track of what VM’s make up an application and then provide failover and write consistency between those VM’s[/stextbox]
ZVM’s are meant to pair to another ZVM at another site so that recovering from a disaster can be automated. This means that if a site fails and takes a ZVM down with it, it’s no big deal; because there is a ZVM at your DR site that has all of the same data as the one at the production site. In a way, they almost act like Active Directory servers do, they all keep each other up to date.
Zerto Virtual Managers are accessible by browsing to https://<ZVM_IP>:9669 and logging in with your vCenter admin credentials.
ZVM summary of duties
- Management GUI for end users and administrators
- REST and PowerShell API management point
- Focal point for all Zerto component communications
- database server for stats, events, metadata, etc
- keeps track of licensing
- handles all interaction with vCenter, vCloud Director, or SCVMM
- deployment and management of VRA’s
ZCM – Zerto Cloud Manager
This is one of the components that normal customers don’t normally use. ZCM is really what enables Zerto to be multi-tenant and provide isolation between customer resources. In a way, it is a manager of managers, as you can manage multiple ZVM deployments from a single ZCM. This enables service providers to create separate pods and
It also is what helps properly configure the networking and deploys ZCC’s according to what your needs are.
Another concept that ZCM adds to Zerto is service profiles. So instead of configuring your VPG’s for each customer, service profiles allow you to create several profiles that customers can then select from. This gives you consistency between customer deployments as well as a way to properly chargeback services to the customer.
Zerto Cloud Managers are accessible by browsing to https://<ZCM_IP>:9989 and logging in with your admin credentials.
ZCM summary of duties
- Manage ZORGs (customer containers)
- Deploy ZCC appliances
- Manage Service profiles
- Manage ZVM Sites
- Control Role Based Access for granular permissions
ZCC – Zerto Cloud Connector
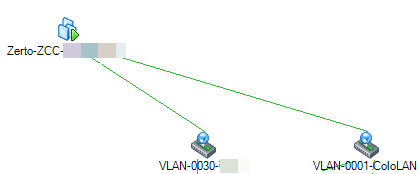
This virtual appliance is a proxy type machine, and you will have one ZCC per customer account. It only has two tasks; the first is to be a pairing target for the customers ZVM instance. The second is to proxy traffic between the customers VLAN and the cloud provider’s management interface.
Generally a client who has two sites would pair their two ZVM’s together. In a cloud provider setting, we aren’t going to let them pair directly to our cloud ZVM. That’s a multi-tenant NO NO! Mainly because they would need direct access to our management network, instead the ZCC has interfaces in both the management port group and the customer port group. This allows Zerto replication traffic from customer port group into the management port group, without compromising the security of the management net.
ZCC summary of duties
- Pairing Target for Customer ZVM
- Proxy replication traffic from Customer VLAN to Management VLAN
ZSSP – Zerto Self Service Portal
This portal is very much the same as the ZVM GUI. The only exception is that it is made for customers to access just their VPG’s during a disaster. It doesn’t let them see any of the service providers infrastructure. Mostly it gives them the ability to perform a failover operation after their ZVM has been lost.
The ZSSP is installed on the Zerto Virtual Manager during ZVM installation.
Zerto Self Service Portal is accessible by browsing to https://<ZVM_IP>:9779 and logging in with your ZORG admin credentials. If you want customers to access the ZSSP you need to use a firewall rule and port forwarding to forward the internal IP and port to an external IP and port.
ZSSP summary of duties
- Provide an guy for customers to perform failovers in the event their ZVM is offline
VRA – Virtual Replication Appliance
If the ZVM is the queen bee, then the VRA would be the worker bee.
VRA’s are the scale-out replication appliances that move the data from production to DR, and then catches the data at the DR site.
VRA summary of duties
- Compress and send data from Prod site to DR
- Catch data from Prod VRA and write it to recovery virtual disks at DR site
VIB Kernel Module
The Zerto kernel module does a LOT of stuff. I’m not going to go into everything it does, but what you will want to know is that it get’s installed when you deploy a VRA to a host. It is non-disruptive during both installation and un-installation. It’s job is to help us get the data that is changing on the production site, and at the DR site it helps during recovery.
Kernel module summary of duties
- Copy change data into the VRA
- Help during recovery type operations at the DR site
Traffic Flow
Now that you understand what all of the components are doing for Zerto let’s talk about how data makes it’s journey from being a production write all the way through to the DR site.
What happens at the production site
The first thing to understand about Zerto is that production writes are NEVER interrupted with Zerto. This is important, because of this Zerto will never affect the performance of the production VM. I always comment that “If your VM was doing 10k IOps before Zerto; it will do 10k IOps with Zerto.”
Once a write is confirmed at the production site the Zerto kernel driver sends a copy up into the VRA that lives on the same host as the production VM. The VRA then compresses the block (if you have compression turned on), and makes the decision on whether to send it to the DR site or to buffer it to ram because the WAN is busy or down.
Once the WAN is ready the block is sent over to the DR site and is received by a VRA that is handling the replication of the VM in question. Each protected VM is assigned to a DR site VRA; it only get’s reassigned if there is a maintenance operation.
What happens at the DR site
Now that the data block is at the DR site the VRA handling it can write it down into the journal VMDK. If WAN compression is enabled the block stays compressed when it lands in the journal. If WAN compression is disabled then the block is written as-is into the journal.
The block will stay in the journal for the duration of the SLA set for each VPG. For example, if you have set a 48 hour journal history, then a block will stay in the journal from the second it lands at the DR site until it ages out. A block ages out after it is older than what the journal history is set to. In this example, that is about 47 hours and 59 minutes. Once that happens, the DR VRA moves the block from the journal to a replica disk.
[stextbox id=”info”]
A replica disk is an identical copy of the production disk. Meaning that if your production VMDK is 100GB then the DR replica disk is 100GB.
The journal disk will vary in size. It’s growth can be limited by setting a maximum size in the VPG, by default the max is set to 150GB per VM. Though, journal VMDK’s will only be about 7-10% of the production disk.
[/stextbox]
Blocks of data in the replica disk are never moved again. Instead they are over-written as needed by newer blocks being moved in from the journal after they have aged out.
Conclusion
Zerto has several moving pieces, but most are deployed automatically during the installation process and never have to be touched by the admin. Most client site installations can be done in under an hour, in most cases, it takes longer to deploy Windows and get it patches and on the customers domain.
On the service provider side, all you are doing is adding a ZCM to a “basic install.”
ZCSP Post Series
This is post 2 of many in a series. I’d love for you to follow along and provide feedback and input as I go. If you are not already following my blog I encourage you to sign up on the right under the sponsor ads. You will only get emails when new posts are published on my blog.
For a list of other articles in this series please visit the series homepage here.
Need more info on how to be or get started with a ZCSP? Let me know.
[mauticform id=”6″]
![]()




As of now we have 403 TB of data or storage allocated to current Production environment. So can you please tell me storage space required for Production site (additional space without current storage space( 403 TB ) ) and for DR site storage requirement.
1. Daily data change rate for those 403 TB is 10 %
2. History (Hours) – 24 Hrs.
3. Failback is also required
My Question here is simple in below
1. How much space needs to be included in production site? Without adding current storage allocated ( 403 TB )?
2. How much space required in DR site to recover 403 TB of data as a whole like journal space, recovery space etc..?
I have to inform the customer how much additional storage needs to be procured in their current production environment and for their new DR environment. Please fill the below blank as per the above information. If you need any other information to calculate the amount storage space required please let me know.
Current environment = 403 TB + ___ ?
DR environment = ___ ?
Hey Nagarajan,
First off we have a tool that can help you know exactly what your average change rate it… its our WAN sizing tool and is available on our support portal. Let me know if you cant grab a copy, and ill get it for you.
Answers:
1. Zerto does not store a journal at the production site, so there is no additional storage footprint required outside of the Zerto components. When that site becomes your DR site though (ie after you have failed over and we start reverse syncing) you will need additional storage for journaling.
2. At DR Zerto keeps the replica disk (403TB) plus the journal disks (+10% according to your calculations). When you start a failover test a scratch disk is also created, it can grow to the same size as your journal hard limit. But it starts at Zerto and only grows as you change data inside of the test machines.
During a Live failover we also use a scratch disk, but once you commit the failover we consolidate the scratch disk, the journal disk, and the replica disk, all into a standard VMDK file.
So my guess, without seeing more details is:
Current environment = 403TB (but remember to have a little extra to use during reverse replication)
DR environment = 403TB + 10% for journal (41TB) = 444TB
Just make sure to run our wan sizing tool to get the exact average change rate which can then be translated into journal size.
Thanks for reading, and if you have any more questions let me know ([email protected]) and I’ll either help you out or get you to your local SE so they can do a deep dive with you.