Update: I have posted a newer article describing how to do preseeding in Zerto Virtual Replication 4.5. Check it out here http://www.jpaul.me/2016/05/zerto-preseeding-howto-4-5u1/
In January I talked about how to use SilverPeak WAN acceleration to boost Zerto Replication so that you could squeeze every last bit out of your WAN connection, but sometimes your WAN is just never going to be enough; enter Sneakernet! In the old days people used to carry data round on magnetic media, often called floppy disks. If you’re like me you entered the world at a much better point in time, and got to skip over most of that ;). After all my first network was a 10Mbps Ethernet that my uncle helped me get going. (Whats Token ring? LOL)
Anyhow, with the size of today’s file servers and databases it is probably not likely that you are going to just kick off replication of a 4TB file server across your 20 Mbps WAN… it comes out to like 22 days to make that happen. So the alternative is to grab a USB disk or a laptop or whatever storage you have and get back to your roots. Basically the concept is simple:
- copy data to portable media
- bring portable media to DR site
- copy data from portable media to vmware datastore
- Tell Zerto where the data is so that it can use it as a seed.
However the first thing you will notice is that VMware doesnt really provide an efficient way to copy VMDK files to portable media. You could do a clone operation to a small NAS NFS datastore and then move the NAS to the DR site, but if you try to get the data “out” of vSphere to say a windows laptop prepare to wait…. and wait and wait. Mainly because of the network stack in ESXi (at least thats my theory). However if we use one of my other favorite tools we can make the process very quick and simple, and not even need to take the production VM offline.
If you’re thinking about Veeam you are right!
Part 1: Use Veeam to copy VMDK’s to DR vSphere
Even if you don’t own Veeam you are still in luck, as we want a Full backup, and we only need one restore point… sounds a lot like a Veeam Zip is all we need! I wont get into the details of how to do a Veeam Backup but there are a bunch of articles out there that should be able to guide you through the process. Because we are using Veeam backup to get the files out of the production environment it should go pretty quick compared to a copy job. Once you have a Veeam backup job completed or a Veeam Zip copy it to portable media… be it a USB drive or a laptop or whatever, then go to your DR site.
Once at the DR site spin up a copy of Veeam. Personally I spun up a virtual machine and installed Veeam on it. I also added in my DR vCenter server as well as a CIFS location as a backup repository. In my case the CIFS path was the location of the USB drive that I shared off of of my laptop. No matter what the case though, make sure to tell Veeam to Import existing Backups, this will get the backup you already did back into Veeam so that you can restore it to the DR vSphere environment. Note the process will be a little different if you are using the free Veeam Backup product.
Once you have your backup files integrated back into Veeam you can right click on the virtual machine you need to create a seed VMDK for and select “Restore VM files” task. In my example I will be creating seed’s for two virtual machines: SharepointWWW and SharepointSQL.
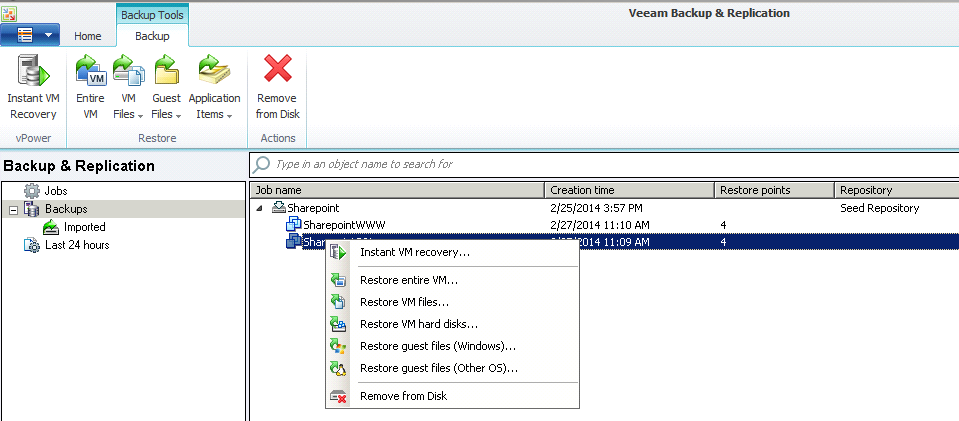
Next you will want to pick a restore point, if you only have one that is fine, or if you have a few like in my example then make sure to pick the latest one.
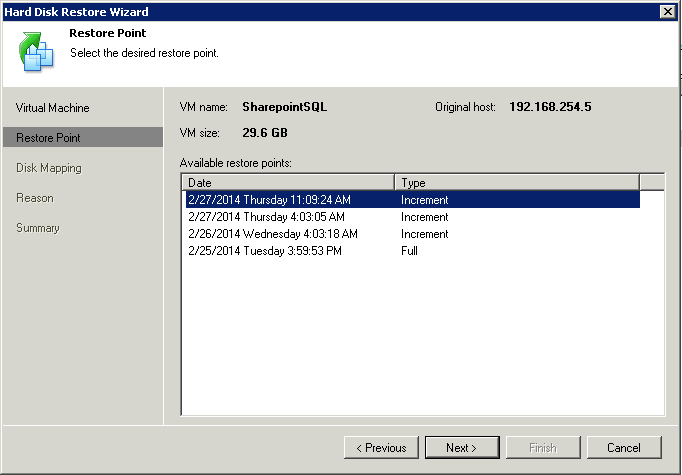
You will then need to pick where to restore the files to, I picked one of my ESXi Hosts, and one of my SAN datastores at the DR site. However there is no need to restore all of the files. You only need the files ending in VMDK. So for the two VM’s that I’m seeding I have a SharepointSQL.vmdk (and its associated flat file) as well as SharepointSQL_1.vmdk (and its associated flat file). For the servers I will be replicating they have a C drive for data and a D drive as a dedicated swap disk. This is recommended so that you don’t waste bandwidth replicating swap file changes.
You can unselect all other files listed except for the vmdk files.
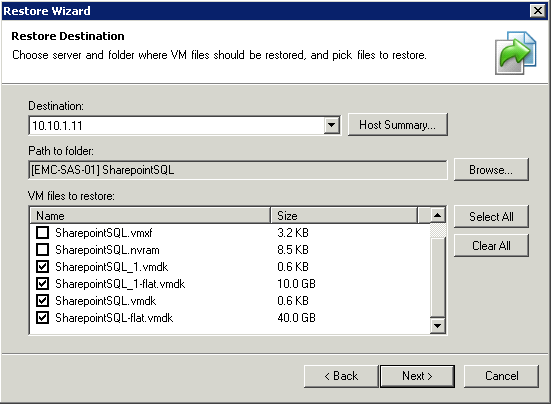
Per normal Veeam wizards you can tell it why you are doing a restore on the next page of the wizard and then you pick finish. The restore process should then kick off. Wait until the restore is completed and then repeat the process for all other VM’s you want to seed that will be in the same VPG. (Note we are doing all the VM’s in a VPG together because the replication looks at VPG’s as a whole so we might as well have all the VM’s that will be in the VPG ready to go before going over to the Zerto interface.)
Once you are done you should have the following files on your datastores (Note that I created a folder for each of the VM’s on my datastores just to keep things clean)

Part 2: Configuring Zerto VPG with Seed disks
Now that we have used Veeam to get our VMDK’s back on to our DR site vSphere environment we can jump into the Zerto Interface and configure the VPG. Add in the VM’s just like you would normally do after youse lect the basic settings on the right.
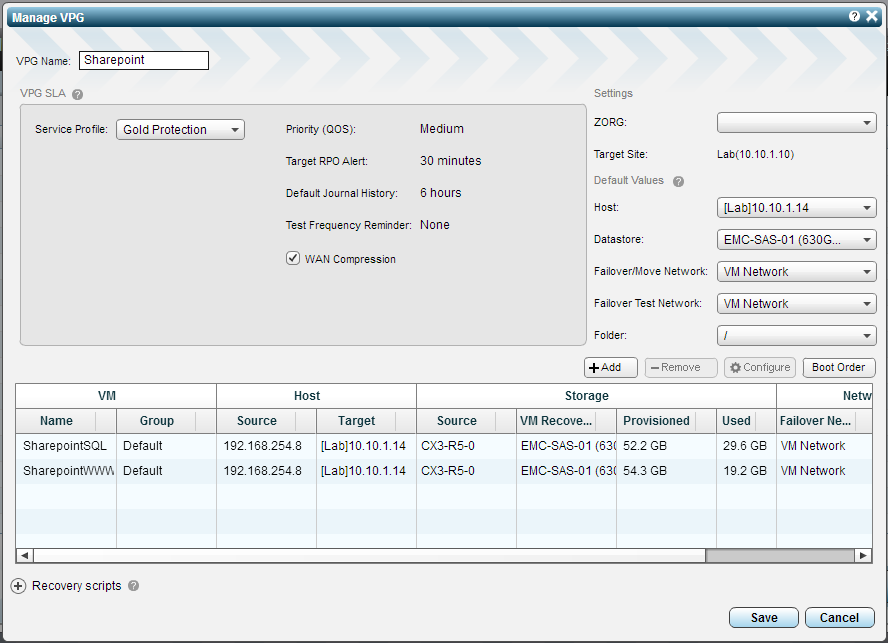
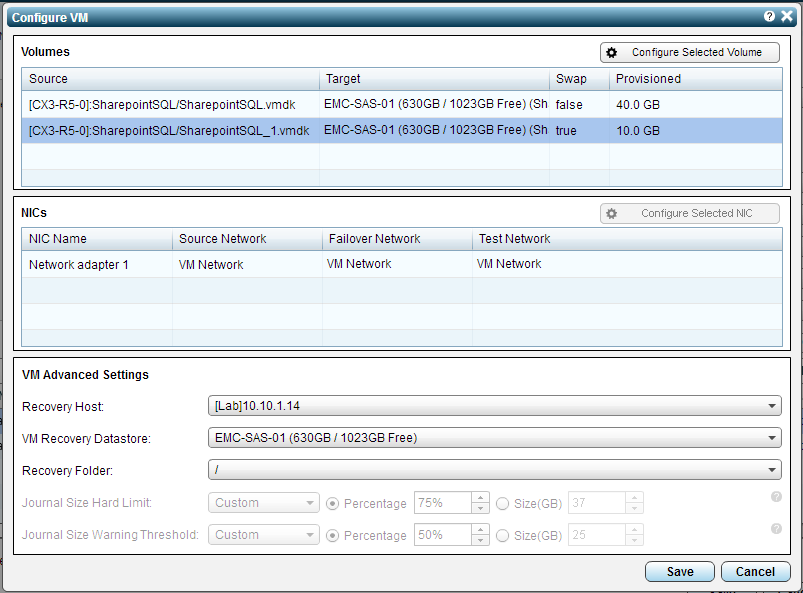
Next select one of the VM’s in the VPG and click on the Configure button. You will see a new screen where you can then select one of the VMDK’s followed by “Configure Selected Volume” at the top.
By default you will see that “Recovery Datastore” is selected, change this to “Preseed” and then select the proper datastore followed by clicking the “Browse” button.
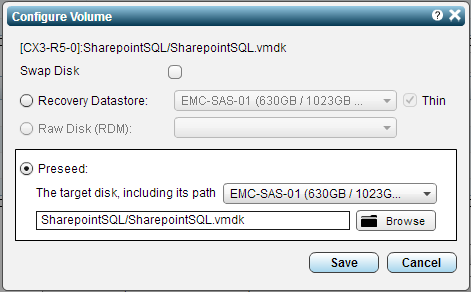
Here you will see a list of the folders on the datastore, expand out the folder that contains the VMDK files for this VM. You will notice that if the size of the source VMDK is different from the DR copy a red triangle will warn you as it is probably not the correct VMDK. select the one with black disk icon instead. You will want to repeat this process for each of the VMDK’s on each of the VM’s in your VPG.
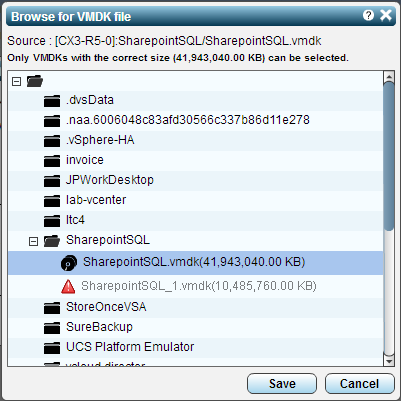
Also remember on the dedicated swap disks to select the “Swap Disk” check box so that Zerto knows that it does not need to replicate any changes for those disks.
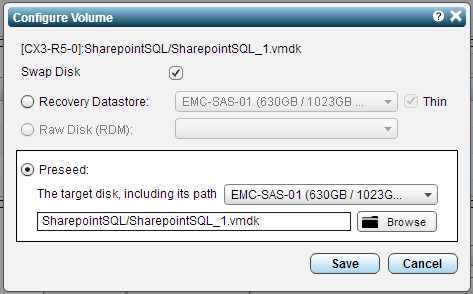
You can adjust other other VPG settings as you normally would such as boot order, or Network IP address changes, etc. Then click “Save” to create the VPG and start the Delta Sync process.
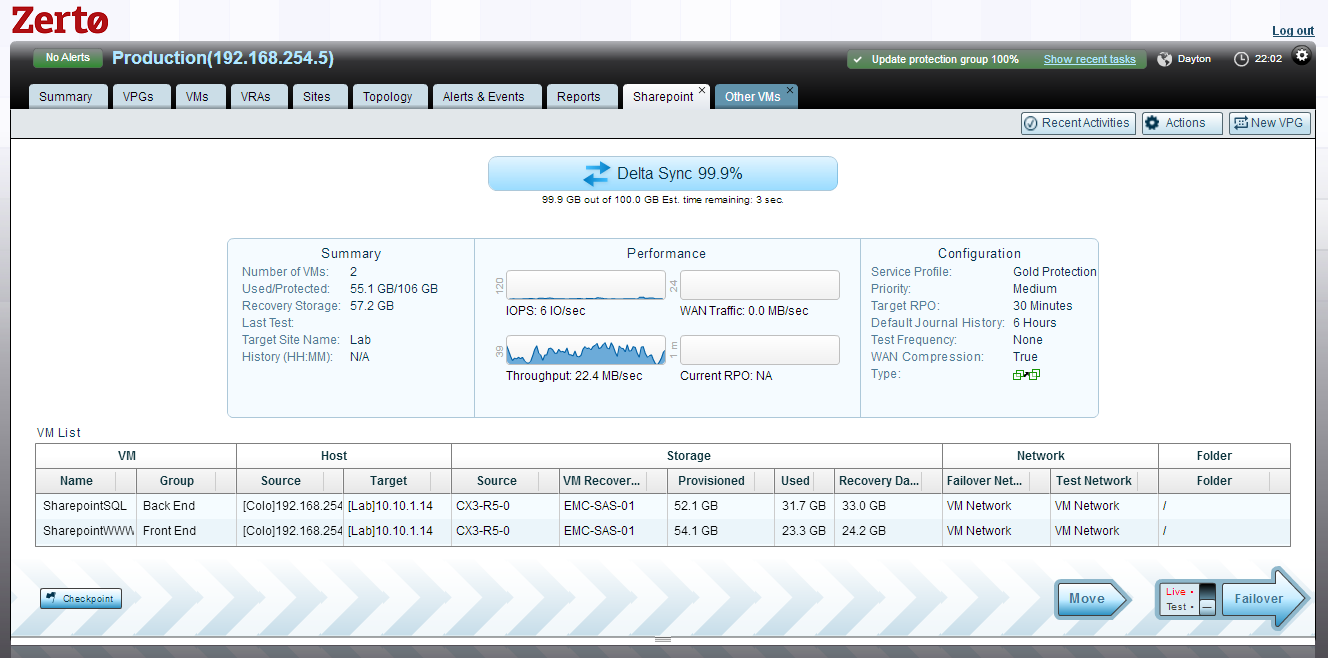
Eventually the Delta Sync will complete and the VPG and its associated VM’s will be in a protected state.
Useless information:
The reason I used seeding this time was because I needed to sync my Dev SharePoint servers to my home lab from my colo. These servers (even with mostly a base install with no information) are around 50GB of data, which is a lot more than my 3 Mbps home connection is capable of. I mean I guess I could have left it run for like 2 weeks straight, but with the lunch and learn events planned for March 18th and 19th (in Cincinnati and Columbus Ohio respectively) I didn’t really have two extra weeks. (Oh yeah, If you want to learn more about Zerto and live close to Cincinnati or Columbus shoot me an email so I can get you an invite… [email protected]) Plus I needed to upgrade RAM in the colo ESXi boxes anyhow so I figured why not kill two birds at the same time.
As for the amount of time I saved….
It took about 20 minutes to Copy the 27GB of Veeam backup files to my Laptop from the HP StoreOnce VSA I use, and another 20 Minutes to copy them to the CIFS location when I got back home. It then took Veeam about 30 minutes to restore all the data to the VNXe SAN. Lastly it took from 6pm to 10pm to complete the Delta Sync across my 3 Mbps WAN connection. So in total it took about 5 hours and 10 minutes… give or take a few minutes.
If I were to try and replicate 50GB over my home connection at the full 3Mbps (which it is unlikely to sustain) it would have taken 35+ hours. so a savings of 30 hours. (if you want to include drive time then add 2 hours… so 7 hours and 10 minutes for doing the seeding)
Either way a savings of 28-30 hours for 50 GB of data !! It was worth the trip.
![]()




I like the pragmatism of using both Veeam and Zerto together. Good work 🙂
Thanks for the info! Do you have a similar post for Zerto 4.0? The interface is different and I don’t see an option to seed the VMDKs.
Thanks!
Hey Kevin,
Ive been meaning to update the posts. But in the mean time check out this video https://www.youtube.com/watch?v=r14UbiEwvpc make sure to bump the resolution to 480 so that its clear.
Here’s a tricky question for you. If i wanted to replicate just the system drives of a SQL Server and NONE of the SQL data. Could I preseed the data drives with blank disk and list them as swap drives? Would that avoid any and all syncing of that drive, or would it still perform an initial sync of the swap labeled drives?
Hey Chris. Technically no.
The reason is that when you pre-seed a vm Zerto does a delta sync first.
Excluding a virtual disk has been talked about as a future feature. I’m not sure on a timeline though.
I think there might be a way to make it work but I’ll have to lab it up. Once I can do that I will post another reply.
I used Veeam 9.5 to create my backups and I have the .vbk file on a external usb drive. I’m a little confused on restore part though. I open up Veeam and click on Restore, I then browse out to the backup file, select it, the file gets read then you select the VM and click Restore. The options are Restore to Azure, Entire VM (including registration) Virtual disks, VM Files (VMDK, VMX) Guest Files (Microsoft Windows) Guest files (Linux and other) I’m assuming I select VM files from reading this article. I then select the destination host, there is an option for Path to folder if I select browse I can see the datastores that I have mounted on that host, what I have mounted on mine are virtual protection groups that I’m using zerto for. Do I restore these files into that vpg? What I’m seeing in that data store are ZeRTO volumes, the Z-VRA.XXXX.LOCAL. Also I’m assuming that I would want to create a New Folder to store those files in.
Hey Lance,
When you restore to the DR site, you just need to restore the VMDK’s to a datastore at the DR site. Zerto will only ask for the VMDK files, we don’t need the VMX or anything else.