If you are a follower of my blog you might remember the Veeam Missing Manuals I put together a long time ago, they were pretty popular and seemed to help a bunch of people. With that said I thought, why not put the same thing together for Zerto?, so here is that post.
Basically the point is just to highlight some of the things that I’ve ran into during installation and use of the product.
Before we get into the meat, remember that with Zerto 3.0 you don’t have to login to the vSphere client to manage Zerto. Just open a browser and go to
https://Zerto Manager>:9669
and login with any credentials that have vSphere administrator rights.
Bandwidth Related Tips
First remember that there is really no replacement for bandwidth. While Zerto does a very good job with compression it is still not a miracle worker(you can only do so much compression), so don’t expect to replicate terabytes of data over a 2 Mbps connection. In fact the minimum supported connection speed is 5Mbps, but depending on the amount of change data in your environment you may need a little (or a lot) more. (Oh and on the converse side Zerto will work with less bandwidth as long as you don’t have much change data… for example I am able to replicate my blog and some other simple VM’s from my colo gear to my home lab over my 4Mbps internet connection without problems… but that doesn’t make it supported LOL)
You can also use WAN optimization products such as Silver Peak to help get data across the wire faster. Stay tuned for a setup guide and some comparison numbers on Silver Peak with Zerto as I plan to set up this combo between my lab and colo.
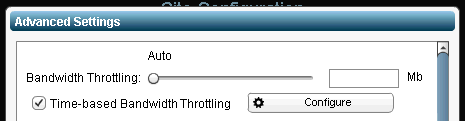
If you do intend to use Zerto’s bandwidth throttling capability and you are an 8-5 type shop, make sure to only limit the bandwidth when you need to and give it full reign when you can.
To make this happen click the Time Based throttling check box:
Then specify the bandwidth limit during business hours.
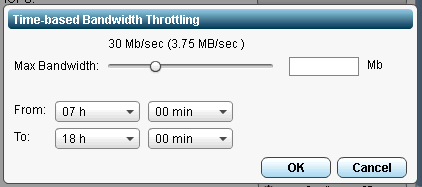
Also make sure to login to each of your sites and specify these throttling limits.
Next, if you are not able to co-locate your DR hardware at your production datacenter to get things in sync before sending it out to the DR site, another great option is to make a copy of the VMDK’s that need to be replicated, and send them via USB drive to the DR site for seeding. One thought is to use the free Veeam Zip product to zip up your VM at the production site, and then restore it to the DR site hardware. Doing this will save you a ton of bandwidth when doing your initial sync.
After the initial sync a great way to save bandwidth going forward is to architect your virtual machines so that they have a separate virtual hard drive (VMDK) for the swap file. Once you separate out the swap file, you can tell Zerto about it and it wont replicate changes to that VMDK. To designate a drive as a swap disk click Edit under Actions on the VPG, and then select the VM and click Configure. You will then see a list of VMDK’s you can then select one and click Configure Volume… inside of that dialog box you will find the check box for swap disk. See screenshot below.
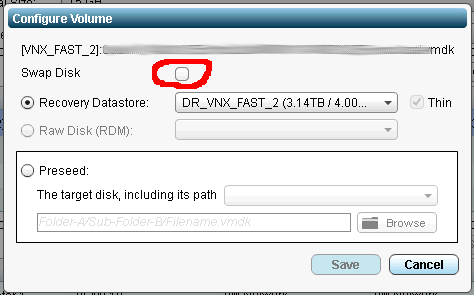
Also you can use this feature for more than just swap disks…. basically all this does is exclude the VMDK from replication… so if you have a VM that has a disk that doesn’t need replicated just tell Zerto that it is a swap disk and it wont replicate any changes that occur on it.
Architecture and Planning Tips
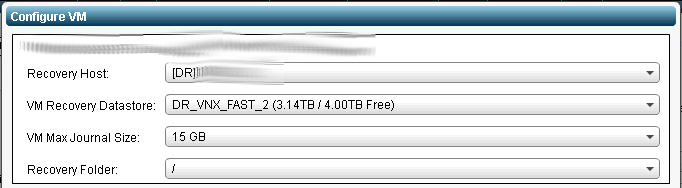
Zerto uses journals to store changes that have been replicated, this is also what allows it to act like a DVR and rewind to any point in time in the journal. By default Zerto sets a maximum journal size of 15GB for each virtual machine, depending on the CDP Journal History setting you choose for your VPG (by default it’s 4 hours) this may or may not be enough space. For some servers that have a lot of writes you will want to up this size to something more appropriate. In simple terms this means that if your VM generates more than 15GB of changes in 4 hours(or whatever journal time you pick) you may need to raise this maximum size to accommodate that change data. If you do not, you will not be able to achieve the amount of history time you asked it to.
Configure the max journal size in the “Configure VM” window.
Speaking of VPG’s, remember that VM’s in a VPG move or failover as a group. There is no way to failover or move just one VM inside of a VPG. Because of this you will want to only put VM’s into a VPG with other related VM’s. For example if you have an application server with a SQL server backend, you would want to put those together in a VPG, so that when you do a failover they come up together at the other side. Otherwise, protect your VM’s by creating them their own VPG as there is no downside (that I can think of) to having many VPG’s (outside of having more buttons to click when you are moving or failing over a bunch of VM’s).
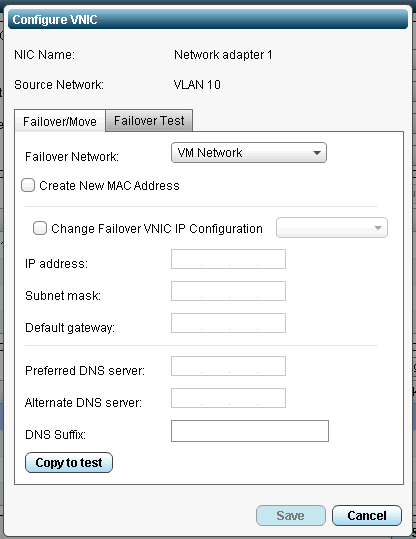
Also in terms of doing moves and failovers, remember to configure your failover/move network settings BEFORE trying to move or failover. If you fail to configure these settings the operation could fail. On this same note, remember that you can have separate settings for your failover testing, so you may want to create a VLAN and a portgroup that is isolated from your production network to allow for easy DR testing.
In this screenshot I have not yet configured the network settings….
Lastly, there is one more tip from Sean at Zerto. (also a big thanks to Sean for providing additional meat to beef up my tips throughout this article)
“Adjust your Target RPO down to less than what the business is demanding, so if the boss is looking for 1hr RPO at best, set Zerto to 30 minutes. This way if there is an issue like a datastore is running out of space or the WAN goes down, we alert you with a comfortable window/buffer of time before you breach your company’s demands.”
As always, thanks for reading! and if I think of any more I will update the post. Oh! and if you have any to add please leave a comment below.
![]()




Nice simple post mate. Well done.
Sean Casey is a great guy 🙂
Different Sean in this case though 🙂
Yeah having two Seans in the office is never an easy thing! Great post, man, and always happy to help!
Next time ill just say the one with no hair 🙂
Great post. One slight correction is that the journal is only stored in the target site. Nothing is written to the local datastore by the Zerto Virtual Replication Appliances.
Thanks Joshua! Ill update my post. That is interesting though, you would think you would need it on both sides just like Recoverpoint 😉
Great post – has helped me understand Zerto better
I am running into one issue with a couple of sql servers that once they complete their initial sync cannot successfully keep up with future delta – I wind up with unusable VPGs.
Do you have any suggestions – I am working with support but hoping someone may have other ideas.
Pingback: Zerto: The Missing Manual - Gestalt IT