I’ve wrote about Veeam in combination with a few different types of deduplication appliances, both Exagrid and Data Domain. One thing that I always hear… no matter which dedupe appliance brand … is the concern about Sure Backup jobs, restore times, and just the general idea that things will be slow once deduped. So after getting an email from Stephan I decided to investigate his idea a little deeper, so if this works for you, thank Stephan.
While I have always said that if a deduplication appliance is sided properly for an environment restores will still be faster than tape, and generally acceptable. However for some it seems that only raw disks will suffice their need for speed. However with the new features of Veeam 7 you can use both raw disk as well as a dedupe appliance and get the best of both worlds.
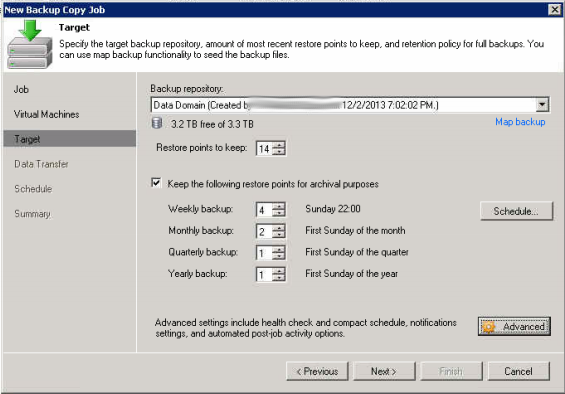
Veeam introduced the ability to copy backups to a secondary location as well as define retention schedules for that secondary location in a format in which many customers were used to (Grandfather, Father, Son). Typically this feature would be used if customers wanted to offload their backups to tape, but we can leverage it for offloading our backups to a dedupe appliance as well. As for a primary location, we can select local disk or any raw disk target that we want so that we can feed our need for speed.
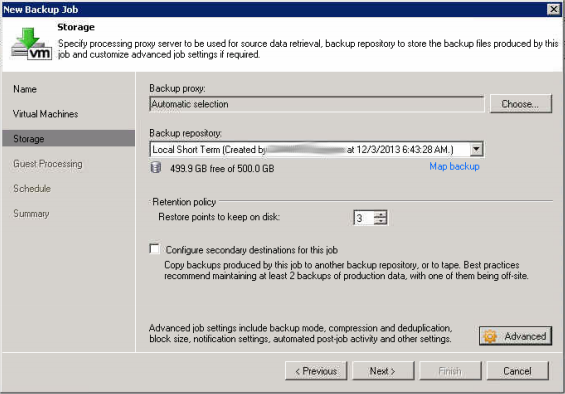
In the screenshots below I am working with a virtual Veeam server that has a 500GB vmdk attached to act as my primary storage target. For secondary storage I have an EMC Data Domain 620 appliance. The goal: Do primary backups to the local attached storage of the Veeam server so that restores as well as SureBackup jobs can be ran from raw disk for super fast speeds. The second goal will be to copy the backups to the DD620 appliance and retain the last 7 daily backups as well as the last 4 weekly, 1 monthly, 1 quarterly, and 1 yearly. In short raw disk will be used for short term storage (say 3 days of retention) and the Data Domain will hold everything (including much older backups).
Step 1: Initial Job Setup
First lets setup our Veeam job to backup our VM’s to the local storage. Do this just like you would do any other job, don’t worry about selecting a secondary location yet.
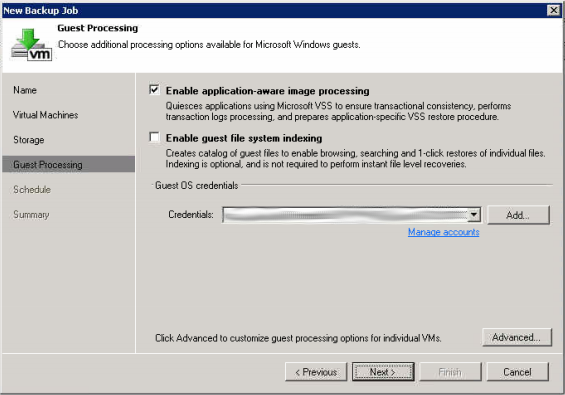
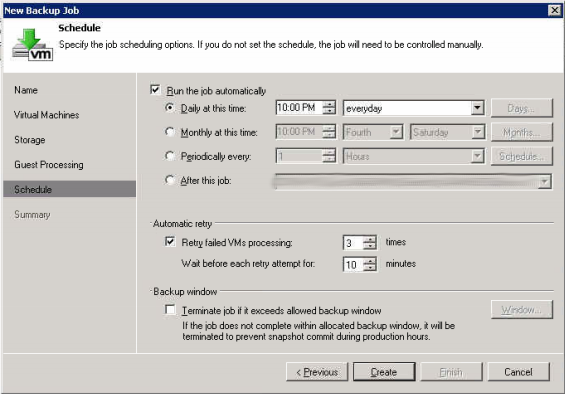
At this point you can run the backup job and should make sure it runs successfully. Once it runs proceed to step 2.
Step 2: Setup Copy Job to Dedupe Appliance
Now that we have done our backup job we need to get the data to the dedupe appliance, right click in the backups window and select “Backup Copy…” to start the copy wizard.
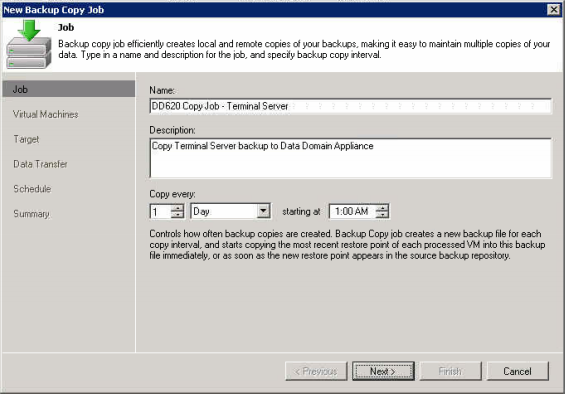
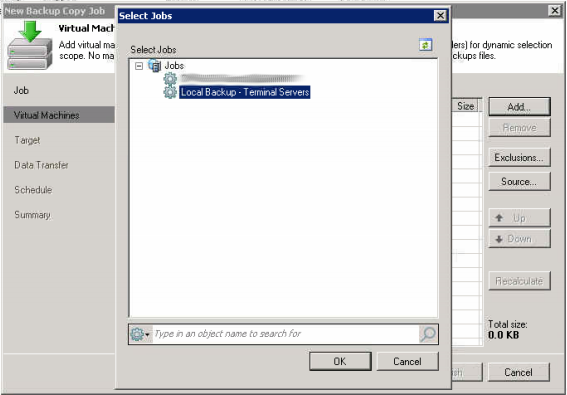


The Results
If you navigate over to the “Backups” section on the left you will see a list of all of the jobs and when you expand the jobs it will show you the VM’s in it as well as the restore points. As you can see Veeam not only keeps the “local” copy we created in step 1 in the backups section, but it also keeps the “deduped” copy and archive retention in this inventory as well under your copy job we created in step 2. So you now have two places to restore from depending on how far back you need to go.
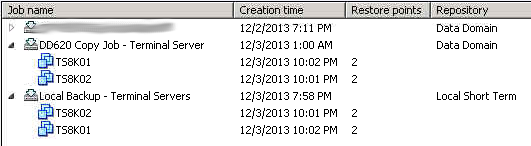
As your retention builds you will start to see that the local copy only keeps around 3 restore points (because thats what we told it to), but the DD620 job continues to add restore points.

Sure Backup
So to answer Stephan’s question… will it make a difference for SureBackup? The answer of course is …. Maybe.
If you have a dedupe appliance that is over worked and cannot keep up in terms of CPU or spindle capacity, it will of course make a HUGE difference. But if you bought a monster dedupe appliance for your needs, then the difference may be minimal if any at all.
Because I’m lazy and wanted to get this post out, I did an entire VM restore from both the data domain and from the local disk. Here is the differences.
Data Domain 620:
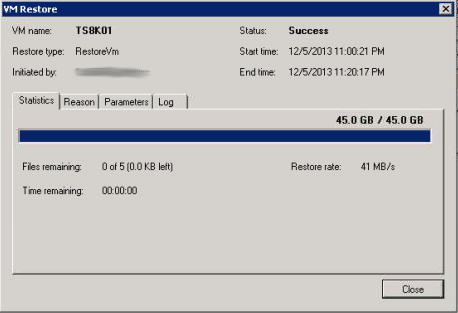
VMDK backed with 900GB 10k SAS drives:
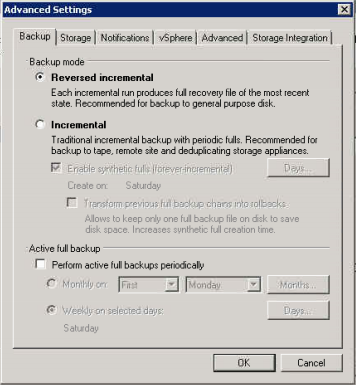
As you would expect the local restore from non-dedupe, non-compressed storage is 2x faster. So in conclusion I would say that if you have plenty of storage space available on your SAN, or local storage on a repurposed server, then why not take advantage of the new secondary location feature in Veeam 7. The rule of thumb is to only keep a few of the latest restore points on that disk and make sure to use reverse incremental so you don’t run out of space too quickly!
As for SureBackup… I would say it’s safe to say that if you get 2x the performance from a restore, then you will certainly get faster results from SureBackup jobs too.
![]()




Great post 🙂
Thanks for the good article!
Our environment is very similar to your setup. Except instead of a DataDomain appliance, we’re using an ExaGrid. I’m finding that the Backup Copy jobs aren’t deduping very well. After collecting about 2 months of GFS copies, the ExaGrid is only able to eke out a 1.16:1 deduplication ratio. However, a newer Veeam backup job is writing directly to the ExaGrid, and that already yielded a 2.5 deduplication ratio, and I expect that to get better over time.
What kind of dedupe ratios are you seeing?
Chances are it has to do with how the data is coming over. But your best bet is to call Exagrid as they (used to anyhow) have product specialist who focus on your backup app.
Are you seeing any performance issues with your Backup Copy Jobs in terms of the weekly/monthly rollup to full backup files? I have a number of BCJs that run to our DD670 (with ES30 expansion shelf) and once they hit retention and need to roll the incrementals up into a full, it takes 2-3 days for that process to complete. Small jobs seem to function ‘ok,’ if there are no more than say, 3-5 VMs. But a couple of our jobs range between 14 -22 VMs and the rollup simply will not complete in sufficient time to restart the BCJ sync and pick up the latest daily copies from the daily backup. I would very much like to see how you might have gotten around this, if you’ve hit retention yet.
At this time, I am looking at running monthly active full jobs straight to the DD670 and avoid the BCJs altogether. Its working on a test subset of our jobs, but even the active fulls are taking a very long time (~20 hours) and I am concerned that if I add more in this manner, I will still run into performance issues. My assessment is that the DD670 is I/O bound simply due to the amount of data I need to copy and the number of spindles it has.
The BCJs work fine when the repository is on our fiber channel SAN array, but we just can’t afford to burn that much storage for the retention policies we have. I am wondering if there is a better way, where we can use the performance of the SAN to run the jobs, but then offload them to the DD670 in some way. Any thoughts you may have on any of this would be greatly appreciated.
Hey Jason, Thanks for checking out my blog!
It’s not uncommon to see those roll ups take a while simply because when your doing a roll-up your forcing the Data domain to do A LOT of reads and writes at the same time…. something that its not really prepared to do while maintaining speed.
HOWEVER… Veeam 8 is supposed to have DD Boost integration, so hopefully it will be able to help out and make things go much faster for you … check out http://www.jpaul.me/?p=8063 for a list of the features in V8.
Other than that though…. Im afraid there isnt too much good news… Veeam Synthetic fulls and roll-ups are like worst case scenario workload for a dedupe appliance 🙂
Sadly, thats kind of what I thought. I am looking forward to version 8 and the potential of DDBoost on our end. We do not currently license the feature, but as long as its included in Veeam 8 Enterprise level (not E+) then we should easily be able to license and implement it. Thanks for the reply!
Pingback: Veeam and Deduplicating Storage | Brian Bunke