Update: With the release of the VNXe3200 all of the issues discussed in this post have been resolved. For a review of the VNXe3200 controller failover process check out my new article: http://www.jpaul.me/2014/08/vnxe-3200-controller-failover-behavior/
Let me start by saying that the purpose of this post is not to say that the EMC VNXe is a bad SAN, it is also not the purpose of this post to say that the HP P2000 I used for comparison is a superior SAN. However, the purpose of this post is simply to spell out how fail-over and fail-back works, and the pitfalls you may encounter if there is a failure. Moreover the information in this article should be considered when planning a VMware vSphere environment where a VNXe is being considered so that applications with real-time or near real-time requirements are properly planned for.
The Problem
Typically when we think of a SAN we think of redundancy, lots of disk drives, and redundant controllers with near instant fail-over. After all the only reason we put all of our eggs in one basket is because we know that if components in a SAN fail we can keep right on going.
Traditionally when a controller or the paths to a controller fail there is redundancy built in so that the servers using that storage simply start asking the other controller for access to it… fail-over takes place. Normally we will also see redundant links from each controller through two separate switches and then those two switches up-link to each server, this provides us with no single point of failure in a typical SAN solution such as an EMC VNX, Hp P2000, or NetApp Filer.
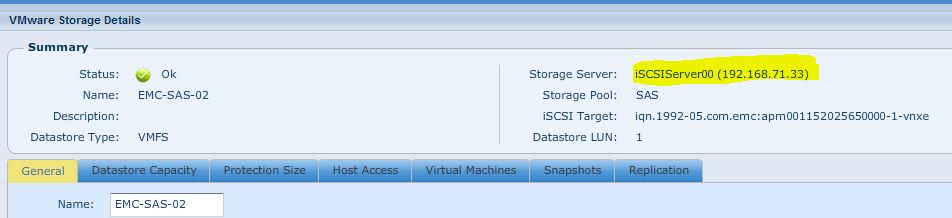
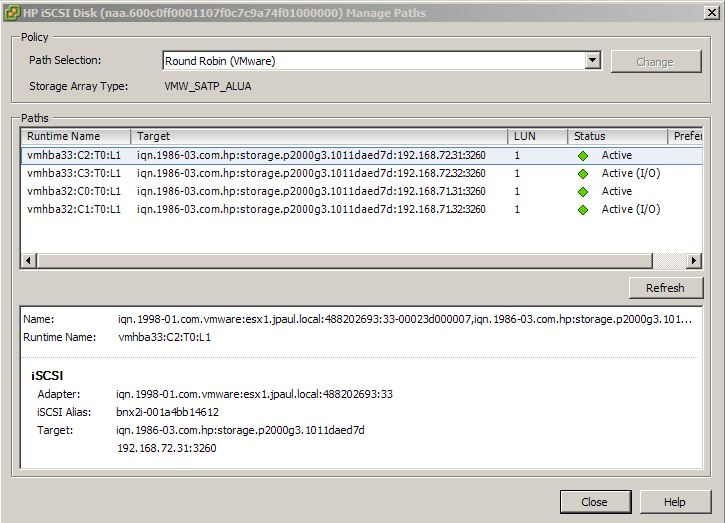
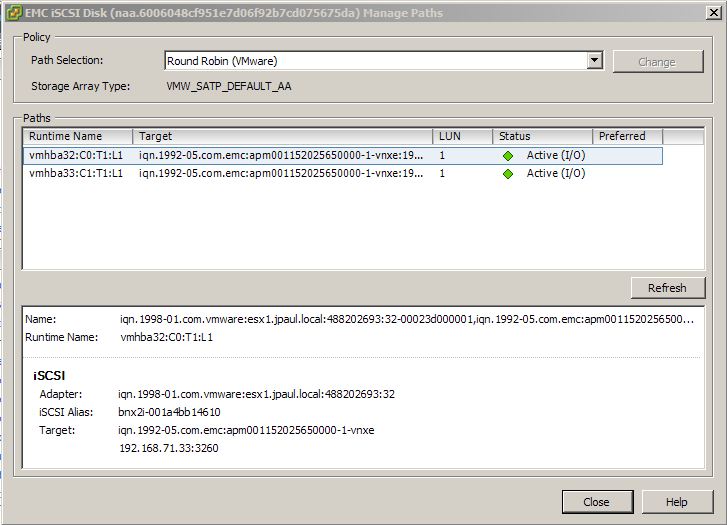
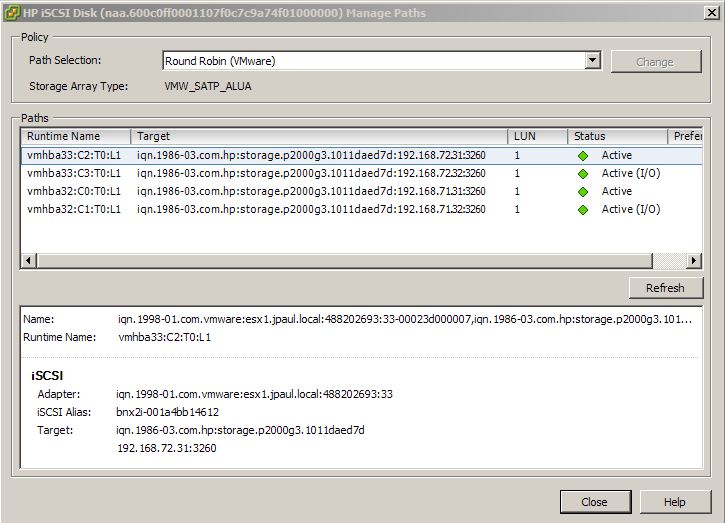
The VNXe is a little different, instead of the traditional block level controllers that serve up iSCSI, EMC is using iSCSI emulation (think like iSCSI target software on linux or windows) that runs like a Windows service on top of the controllers operating system. So when a controller is put into maintenance mode for a firmware upgrade or when it just fails in general, there is no graceful transition to the sister controller. Instead it is just like a service that has stopped responding. Then after a short period of time, the sister controller starts that service on itself and storage I/O resumes. In my tests this process of fail-over took approximately 2 minutes, during which time a file transfer that I was doing was frozen as was all other I/O in the affected VM. However I will note that the transfer did complete without error. For more information on this you can go into the properties of one of your VMware datastores and click the “Manage Paths” button. Normally on most SAN’s you will see 4 paths, two that are “Active (I/O)” and two that are just “Active” if you are using Round Robin NMP. 
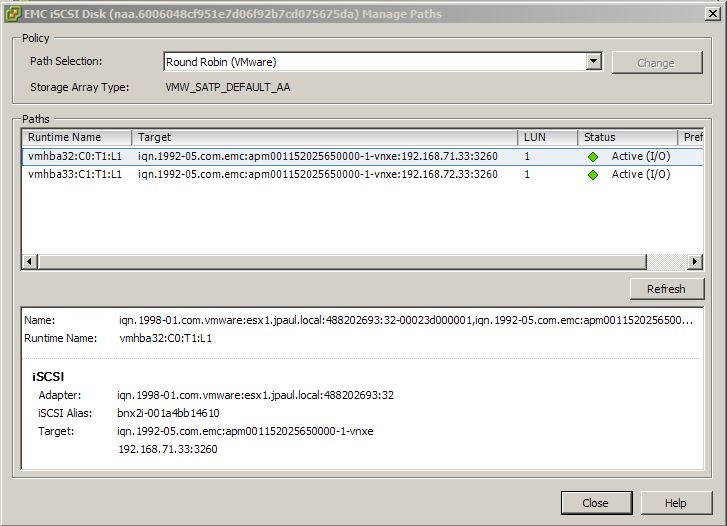
In this picture you can tell that storage is viewable from each controller because in the target string you can see both 192.168.71.31 and 192.168.72.31 (which are on controller A) as well as 192.168.71.32 and 192.168.72.32 (which are on controller B).
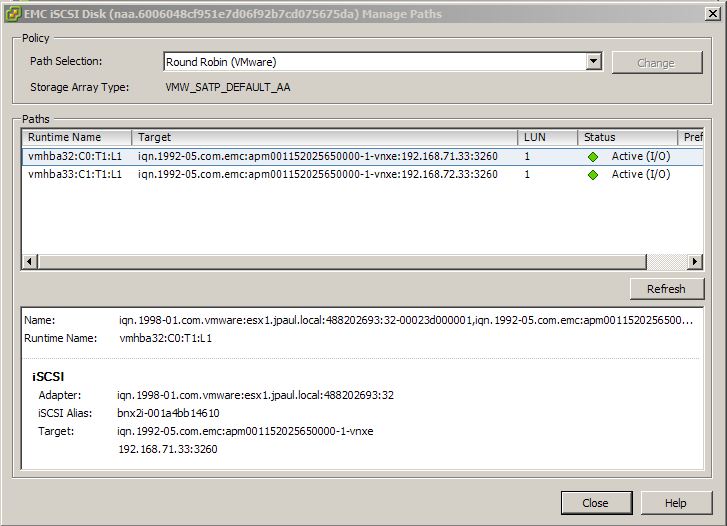
However if you look at a VNXe datastore you will only see two “Active (I/O)” paths and no other paths. The reason for this is because a normal SAN uses ALUA which makes storage available on all ports, but the controller that owns the LUN holds the optimal ports. The VNXe only shows the LUN out the ports on the controller running the iSCSI server that owns the LUN, the other controller has no information about those LUNs until the iSCSI Server service owning then is failed over to it.

In this screenshot you can see that only Controller A (the owner) is presenting the storage because we only see its IP addresses here (192.168.71.33 and 192.168.71.34).
So the moral of the story is that if you are going to use a VNXe on your project you need to make sure that whatever workload you are running on it can sustain a period of time where all resources on it are unavailable. For some companies this is no problem at all. As long as there is no data loss and the system recovers from the problem things are fine. However I can think of other situations where 2 minutes of downtime would be a problem, specifically I am thinking of PLC’s or other sensors that send real-time manufacturing data back to a database. Downtime of that length where SQL services are not responding could in some cases cause that machine to slow down or stop. So the bottom line is to make sure you know your workload and what requirements it has.
My Testing
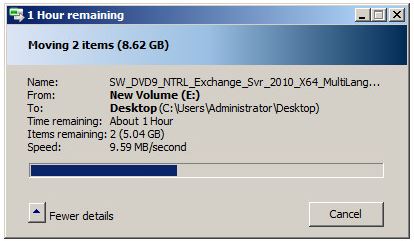
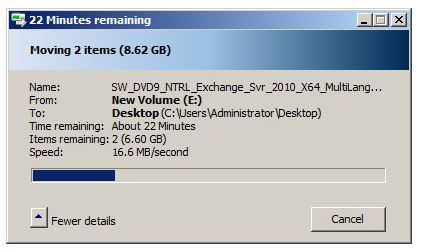
To test my suspicions I used a VNXe 3100 running the latest firmware as well as an HP P2000 G3 array with the latest firmware. Then I configured iSCSI as I normally would with two separate subnets and switching fabrics, after that I created LUN’s on each array and presented them as VMware Datastores, and finally I created a Windows 2008 R2 server with enough space to conduct a fairly large file transfer. To see when there was no active I/O happening I was moving two large ISO files back and forth between two locations in the VM.
First lets look at the performance graph of the HP P2000 SAN.
![]()
In this picture you can see when I took the owning controller offline, denoted in the picture by ” Controller offline”, and after it goes offline you can see a brief period where I/O is reduced (it was less then 20 seconds) and then you can see that the transfer rate jumps right back up to where it was before the controller went offline. The only difference was a little bit higher latency, but the VM was still usable. to the far right of this picture you can also see where I brought the controller back online, and for a split second I/O is interupted but it was almost undetectable to me, if the graph wouldnt have shown the increased latency and downward spike I would have not noticed it. Overall the P2000 preformed exactly how I expected it too, which is also how I would expect a VNX or other traditional array to work.
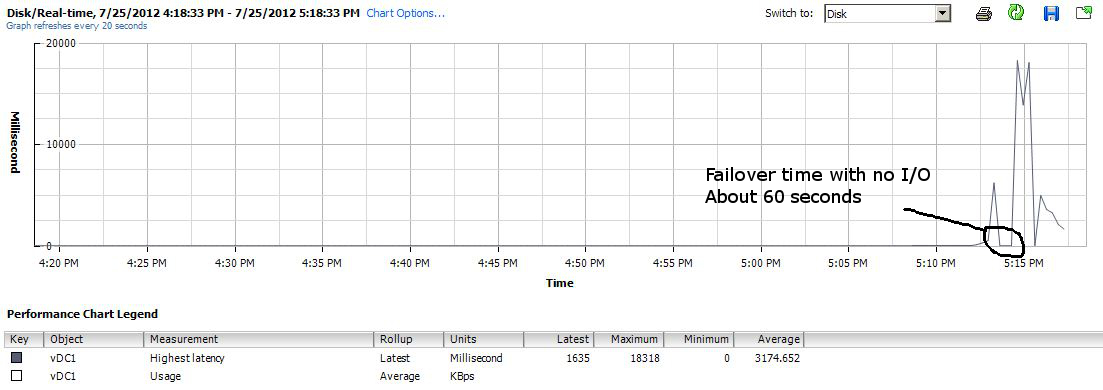
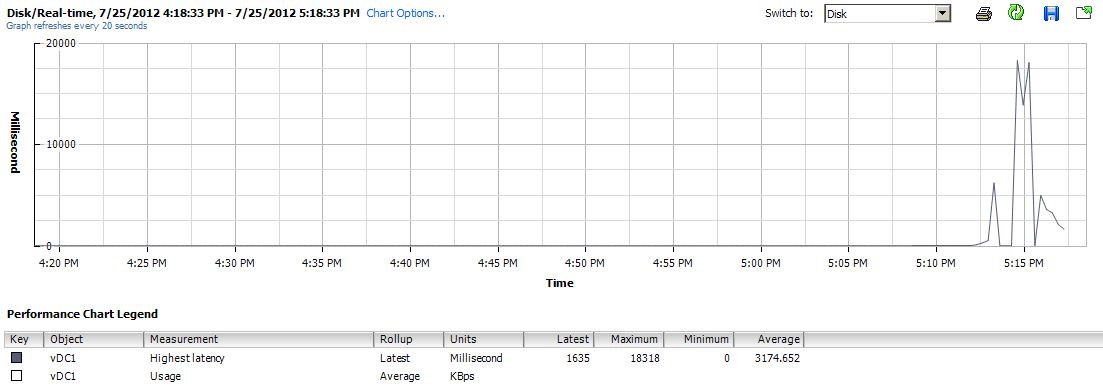
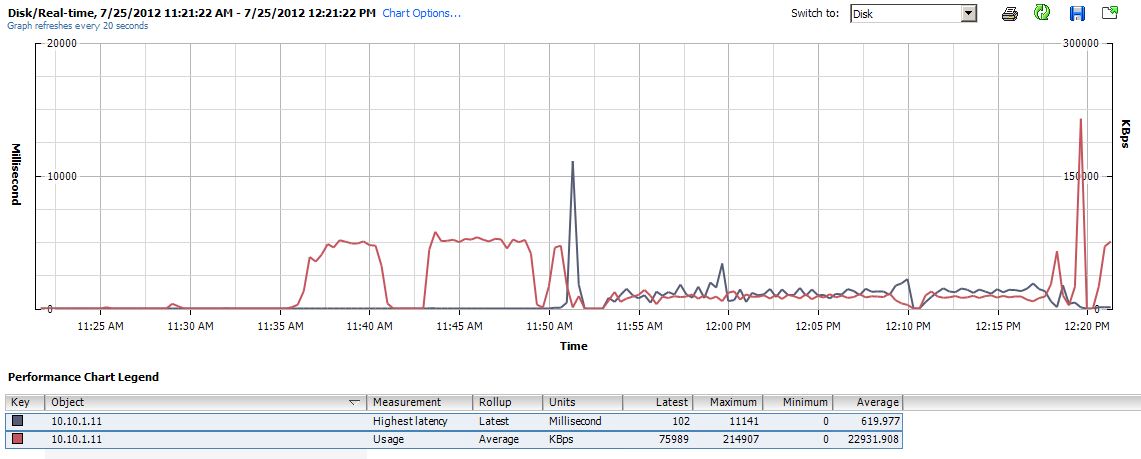
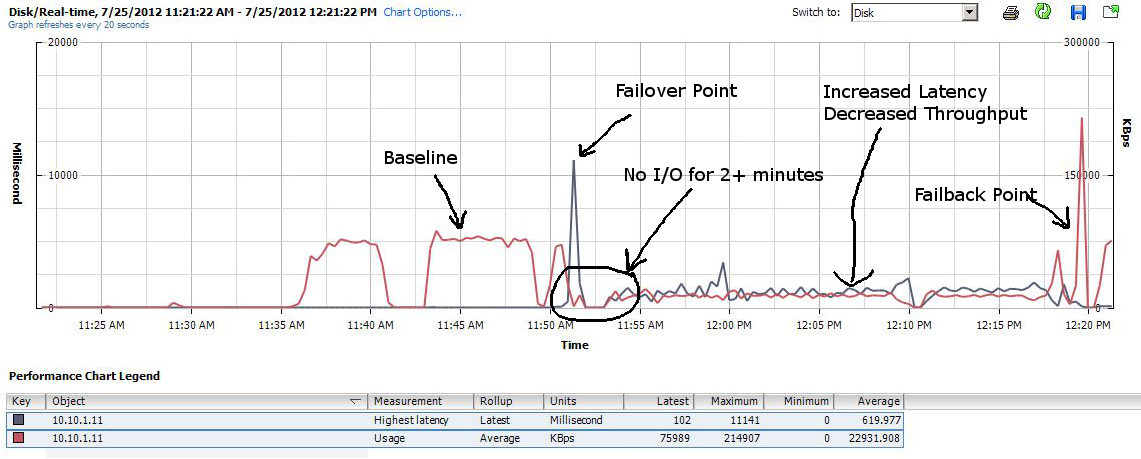
Now lets look at the VNXe graph.

In this picture we have a lot to talk about. First on the left side we can see two pretty normal looking spikes, the first is where I transfered the ISO files from the NAS to the virtual server. The second hump is where I transfered them between locations inside of the VM just to get an idea of what to expect under normal operations. Then the third red hump is where I started the move again, but after a short time I put the owning controller into maintenance mode. This caused a huge jump in latency which I expected, but then it took more then 2 minutes for the iSCSIserver00 service to fail over to the other controller. After it did finally fail over the transfer rate on the move fell from about 40MB/s to about 8 and stayed there through-out the completion of the move. Latency also hovered around 600ms, where as the P2000 was in the 150ms range. After letting it finish the move, I started the move again and then rebooted the offline controller eventually bringing it back online. When it did come online there was a spike of throughput for about 10 seconds, and then things returned to normal in the 40ish MB/s range.
The main concern I had was the amount of time to fail over the iSCSIserver process to the sister controller, but I have to also mention that the VM was almost unusable while finishing up the transfer. It took a very long time to even open Internet Explorer.
NFS on VNXe
I also did the same test with an NFS datastore and when the owning controller is rebooted or taken offline for any reason the same thing happens. However the amount of time while things are offline is reduced to about 1 minute according to the performance graphs.

Conclusions
To sum things up, I want to reiterate that the VNXe is not a bad solution, but you do need to be aware of how it works so that you can determine if its quirks will fit your business need or if you need to select something more traditional like an EMC VNX or other brand.
Think of it like this, if you are given the choice of Goodyear Run-Flat Tires or an “in the trunk” spare tire, which would you rather have? Either one will get you down the road until you get the problem fixed, but one involves a bunch more time along the side of the road then the other.
Here are some other screenshots I took during the testing.






![]()


Great article Justin, thank you.
Would something like this cause data corruption for Exchange or SQL, or just slow or no response for 1-2 minutes?
It should not cause data corruption, but there will be *no* response while its restarting the iSCSI or NFS server, and when I tested it, it was slow as heck until the other controller came back online and failed back
Reducing TcpMaxDataRetransmissions on the client from the the default value of 5 to, say 3, can decrease the iscsi failover time, especially for iscsi writes. Iscsi failover can vary quite a bit based on when in the sequence of activity the target failover occurs.
Thanks for the tip Rick, is this something you typically do for any SAN or just for the VNXe ?
Justin am I reading the EMC pathing screenshot incorrectly or is it a typo?
You say that the EMC controllers are on 172.168.71.33 & 192.168.71.34 but the paths are showing as x.x.71.33 & x.x.72.33? This sort of points to a single path off both SPA and SPB?
cheers
The paths are 192.168.71.33 and 192.168.72.33 they their masks’ are 255.255.255.0 so they are in different subnets with no IP reachability between them, If you look in the additional screenshots for the shot with only two paths you will see that the VNXe has two paths. As for the 172.168.71.33 … i must have made a typo and will correct that .
Hi Justin. In reading through the comments, I suspect part of the reason you may be having such poor latency and bandwidth is due to the SPs being on different subnets. Depending on your switch config, there very likely is a vlan mismatch and/or routing issue going on.
While using different subnets has historically been the “correct” way to do things w/ most storage, the way the VNXe works will cause issues for you when SPa takes over for SPb. Essentially, if SPa is expecting vlan “71” (or whatever number corresponds to 192.168.71.0/24) and then takes over for SPb (which presumably is on another vlan to accommodate 192.168.72.0/24) there will inevitably be a vlan mismatch. Worst case, I wouldn’t expect connectivity to LUNs previously mapped to SPb to work at all. Best case, I suspect there must be some routing going on and that would likely account for the bizarrely high latency combined with the poor bandwidth depending on the switch/routing infrastructure in place.
I’m obviously making assumptions on some of the networking config in place, but suspect that is the source of the poor performance in your testing.
As to the actual failover time, I’d be interested in seeing what impact (if any) changing the SP IP addresses to be on the same subnet would have on recovery time.
disclosure: I work for an EMC partner. That said, I’m not trying to be overly biased towards the VNXe as I do believe it has some noteworthy limitations. I’m just interested in seeing if the performance issues you’ve reported can be mitigated by changing the network config.
Going yo have to agree with peter b. Did you have a router that can cray traffic nineteen the vlans? Every one tries to cross over the vlans, but ethernet groups must be connected to the same switch. (so if you have the io module, then maybe you have eth9-11 a a guppy plugged into the switch A, then make sure you do the same with the same eth group from the second controller. Otherwise what we tend to see is storage controller failover and paths on the up controller not fuctioning optimally. The service is virtual s you say, but its using a virtual ip, that transitions almost immediately at failure, as opposed to “starting up”. Did you address this with their tech support or your regional emc technical sales person?
One problem is your useing a VNXe … The VNXe’s have a virtural bridge between the 2 processors while a VNX has a physical one. Another point is what fail over software are you using? Using round robin is is a bad idea for ISCSI, forcing it to try the one path and if it fails a retry before changing to the other port. Powerpath will have already sent a ( well call it a ping) down the path before the IO is sent so it would have known the path is down and not tried just send the informaion waiting for a fail.
Over all it is good to show that yes a vnxe can be used and yes it will fail over but use it for what it was made for. It is a NAS that people are trying to use as a SAN for cost. If cost is the main issue then you should know your going to take a hit somewhere. i would like to see this same test ( besides the network issues) with a VNX and powerpath VE.
I know this blog post is a year old, but wondered if the suggestions made in the comments (that the problem is caused by the IP addresses of the controllers being on different subnets) was the cause of the problem?
Very informative post, even if the problem is caused by the subnet.
nope, ive setup a bunch of VNXe’s and its always been the same. I am told that the next generation VNXe box will run the same firmware as the VNX2’s and will not suffer from this problem…. time will tell i guess.
I have two VNXe 3100s. I use them as NFS servers for my KVM Virtual Machines. Everytime, one fails over, it causes all partitions on all Linux based virtual machines to go into read-only mode. When this happens, I’m forced to reboot all of them so they can do disk checks and bring them back up read/write.
When this hits my production environment, it is a major issue. EMC keeps bugging me to buy more VNX devices. Not a chance.
VNX devices are completely different. on Storage processor failover, however because NFS storage would still go through a datamover you would have the same issues.
Im told the VNXe’s will get updated with the new code when VNX2 comes out and it should fix some of the issues, however since NFS is still a file side service i would bet money it will still have to drop… then be restarted.
Dave,
You have fix this by changing the timeout for EXT3/4.. it’s set pretty low by default if I recall.
On the flip side: I’m looking at the VNXe-3150 right now, and trying to see if the iscsi issues for failover have been fixed or not. any updates?
All VNXe series systems operate on the same code… so nope not that i have seen
Also I dont know that there is any plans to fix this. I believe that EMC plans to focus mainly on updates to the VNX2 series of systems this year… haven’t heard much about the VNXe line… not to say there isnt something in the roadmap, but i just dont have any information on it.
Pingback: VNXe 3200 Controller Failover Behavior | Justin's IT Blog
Great article, we need to discuss with a customer that change VNX3150 for a VNx3200 and we need to explaint this point, for FCP is more o less the same thinkg (VNXe 3100) for this reason you need to change default values in iscsi initiators in both (windows or vmware) in order to propoer handles the 2 minutes timeout