Two years ago I posted an article describing how the VNXe3100 (and 3300 and 3150) had a major drawback in the way that it handled IO during a controller reboot or failure. If you didn’t get a chance to experience this for yourself head over to my older article and take a quick look http://www.jpaul.me/2012/07/vnxe-sp-failover-compared-to-other-solutions/.
Now that you know what the issue was, let’s talk about the new VNXe3200. I received a demo box from the folks at EMC through Chad Sakac’s blog a couple of weeks ago and have finally gotten a chance to play around with it and re-do the same test that I did 2 years ago to the 3200’s predecessor. The results were awesome, but before I go into the details let me just say that I no longer dread when I have to propose a VNXe. I now know first hand that this box is up to the task and should have no problems living up to the reputation of its big brothers (the VNX series).
Why is the 3200 different

So the VNXe 3200 borrows the heart of the VNX… it’s MCx code… It then uses that code to provide native iSCSI (not emulated like all previous VNXe’s) as well as Fiber Channel connectivity…. Simply put this thing has big boy block protocols. Because of this there are services running on both SP’s at the same time and no service “reboot” time is needed like the older systems needed when restarting their iSCSI servers.
I’m not going to go into all the other new awesomeness as there will be lots of other posts about this box on the way, so let’s get into what happen during the failover tests.
Background Info
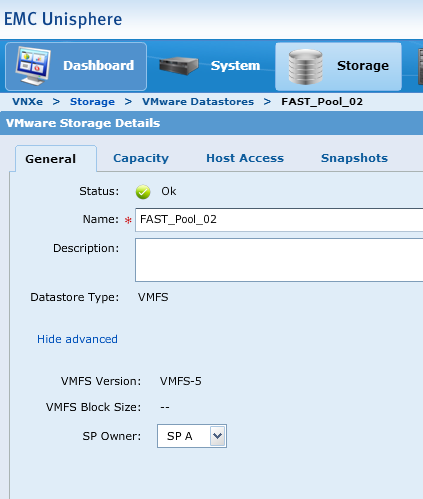
From the VNXe 3200 I have presented two LUNs to my VMware ESXi servers. The virtual machine I will be using to test with (SQLAO1) is on a LUN named “FAST_Pool_02” (and yes the VNXe3200 also has Fully Automated Storage Tiering, just like the VNX series). Here is a screen shot showing that SPA is the owner of this LUN, again, very different from the previous VNXe’s. On those model’s LUN’s were owned by an iSCSI server not a storage processor.
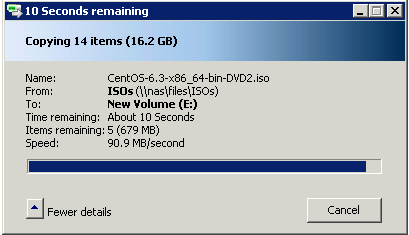
So to do the test I decided I would copy 16.2GB of linux ISO files from my VNXe3100 CIFS share to this VM.
Baseline
The first time that I transferred the 16.2GB of ISO files I was getting between 80-90MB/s as reported by windows.
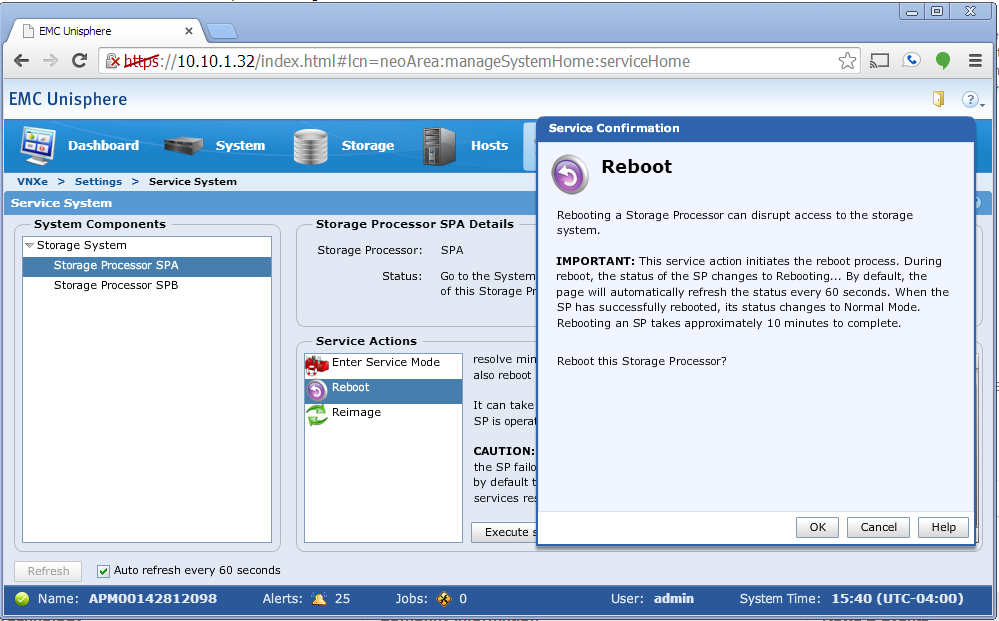
Bouncing SPA
The next thing to do was to kill SPA, to do that I decided that the garage was too far to walk to so I used the SP Reboot feature in the Service System menu.
By the time that I rebooted the SP I already had the transfer running a second time. In fact it was probably half way through the transfer. When I did that Windows kept right on copying data, buffering it inside of windows for a short time. I attribute this buffering time to VMware and its native multipathing policies, because within a few seconds the buffer started flushing out just as fast as it built up. On the VMware Disk Performance graph for the SQLAO1 VM, you can see that traffic spikes down when the paths switch over, but then immediately spike back up as it starts to use the other paths through SPB.
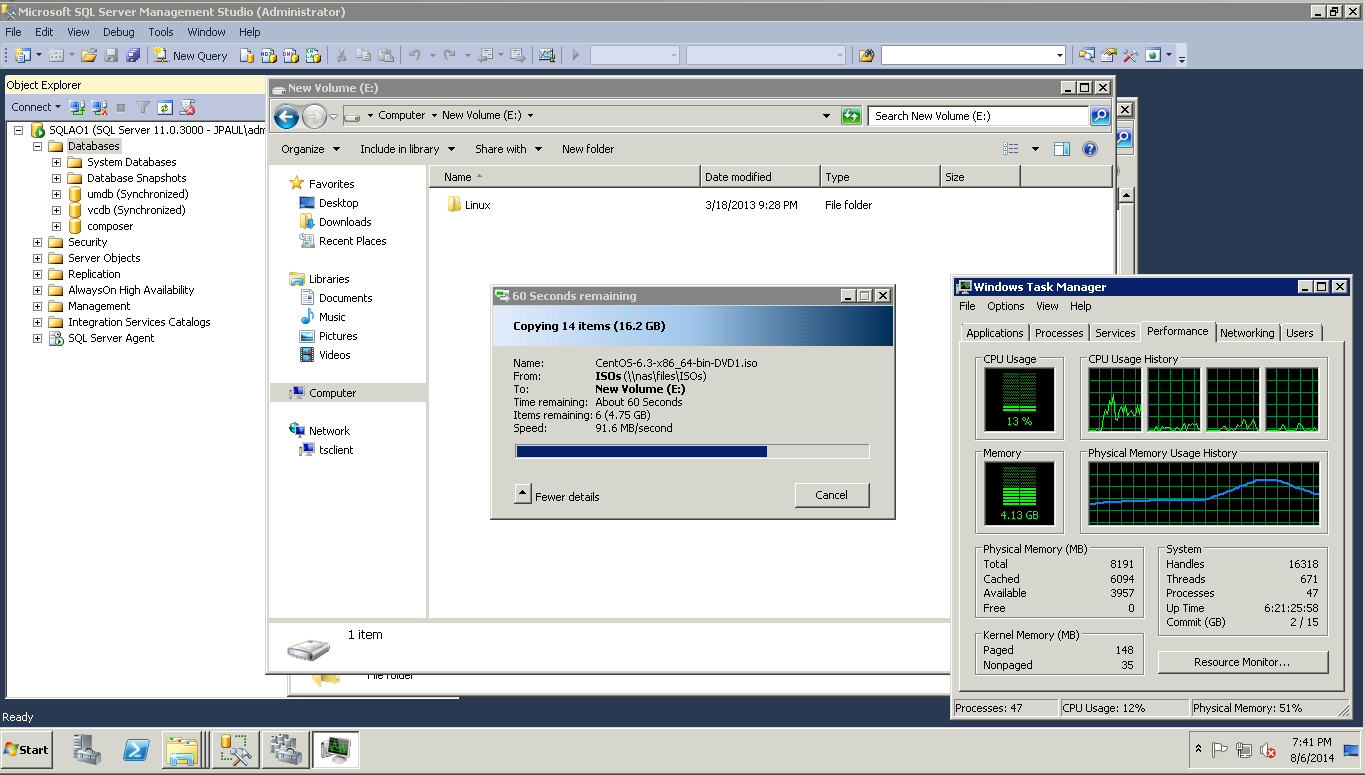
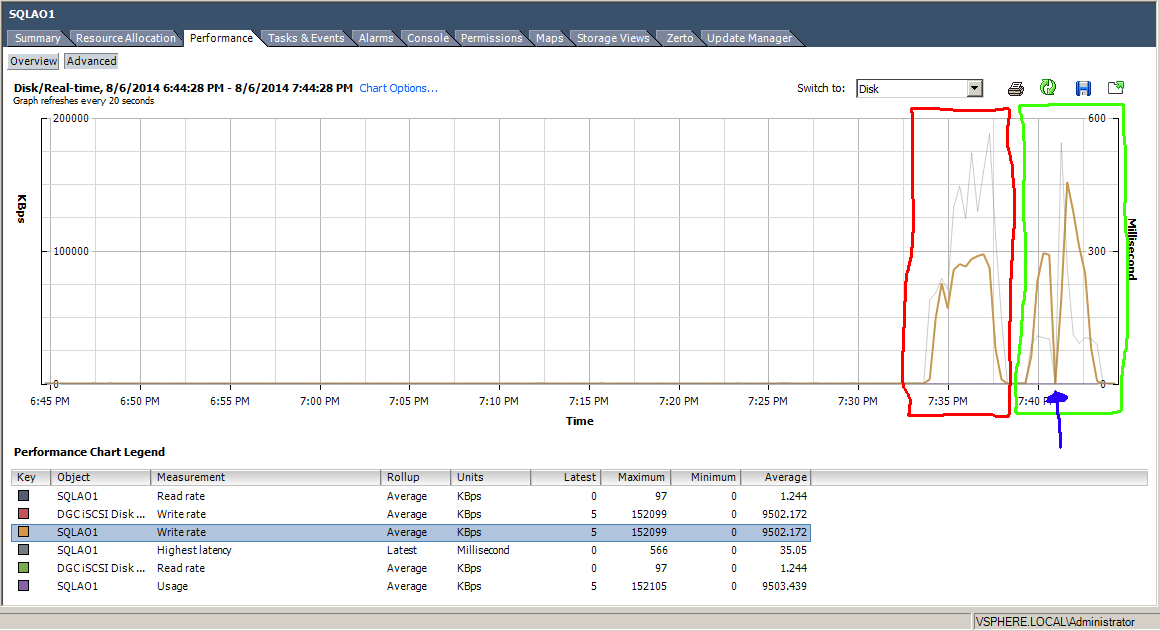
As you can see the transfer is being limited by my 1Gbps network, because right after the path switch over, VMware dumps all of the data that has been buffering for the last 10ish seconds to the SAN and is able to spike up to 150MBps because of multipathing (BTW I just have 2 x 1Gbps links and IOPS Limit = 1 on the ESXi host).
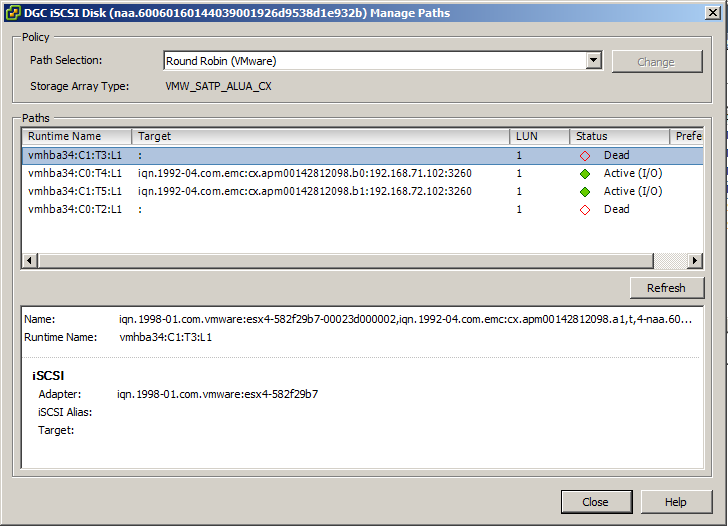
The total time it took from when I clicked reboot until when the paths were back online and active was about 9 minutes. During that time I grabbed a screenshot of the paths list in VMware, showing that b0 and b1 ports were in use.
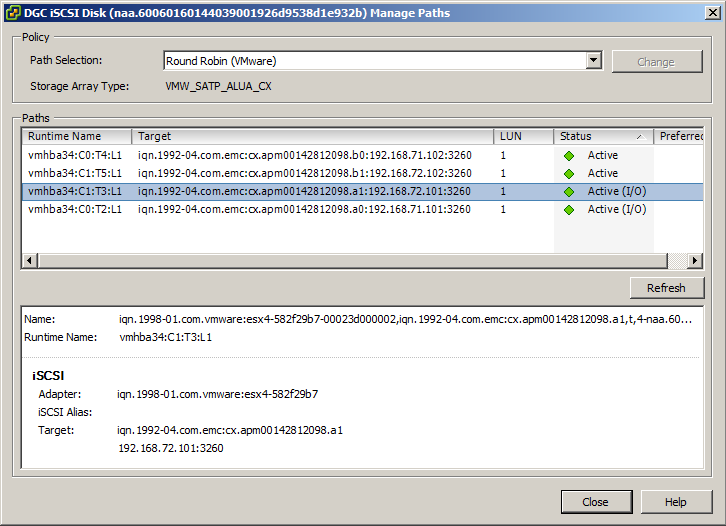
After the reboot was completed I checked the paths again and it had automatically failed back to SPA as the owning controller.
Takeaway
I’ve only had the box operational a week, maybe two at the most and already I am certainly impressed. EMC has fixed a lot of the major issues that I had with the older VNXe series. In fact I’m not entirely convinced that they should even call this box a VNXe…. but that is another post coming soon.
I see this box being a great addition to my consultant tool kit. Knowing that the VNX5100 is going away at some point, it left a small hole for the customers that needed enterprise SAN functionality in a cost-effective platform. However with the addition of FAST VP and Fast Cache into the VNXe 3200 as well as Fiber Channel and native iSCSI; it’s not hard to figure out why they picked code name KittyHawk… cause this thing does fly compared to its older brothers.
Stay tuned, more VNXe3200 articles coming as I have time to get them posted.
Disclaimer: EMC has provided a VNXe3200 Demo unit for me to perform these tests with. They however have encouraged everyone in the demo program to post the good the bad and the ugly all the same. I am not being compensated for this article or any of the other EMC articles posted on my site. In fact it actually costs me money because I haven’t figured out how to get the power company to sponsor my lab yet 🙂
![]()


Pingback: VNXe Controller failover compared to other SAN devices | Justin's IT Blog
Hi
I’m planning on connecting (if possible) 2 x ESXi host and 1 x windows 2008 R2 server to a VNXe 3200. Is there anyway of doing this without using switches?
Thank you.
Hi
A stupid questions maybe.. but, I’m planning on connecting (if possible) 2 x ESXi host and 1 x windows 2008 R2 server to a VNXe 3200. Is there anyway of doing this without using switches?
Thank you.
yup… get 6 fiber cables, 3 – dual port HBA’s (one for each physical host) and cable them up.
alternatively you could get 6 single port HBA’s too.
Hi, is VNXe 3200 compatible with HP StorageWorks 8/20q?
I can’t find an HCL…
thanks in advance
Hi, is the VMXe 3200 compatible with HP StorageWorks 8/20q?
Thank you in advance.
I wouldnt see why it wouldnt be. The 8/20q is a simple Fiber Channel switch. Just make sure to get the fiber channel add-on card in the 3200
Fiber Channel is fiber channel. Its like asking if a Cisco Switch is compatible with an HP switch. They speak the same language so they should work fine. But you probably arent going to find an HCL that has HP switching for an EMC san. As EMC resells both Cisco MDS and Brocade Fiber channel switches.
Ok , thank you.
I heard about an incompatibility with FC SAN and FC card (maybe a wrong source …), so i was worry about a same issue with FC switch.
Enr “Noob” :\
No problem. As long as the speeds that the card and the switch operate at are supported by each other you should be fine.
But i think almost all hardware these days supports 2/4/8Gbps
so unless you have a 16Gbps switch and like a 2Gbps card you should be good. (and even if you have that combo it might work …)
Have you tested failover of NFS and CIFS services? I’ve played around with the Unisphere demo and it seems like that’s not really a thing on the VNXe3200. I haven’t been able to download the manual yet since I’m not (yet?) an EMC customer.
i havent tested it, but i can if you would like to see what it does. But since CIFS and NFS are session based services i have to think that sessions would be terminated and then clients would need to reconnect once the services restarted on the peer SP
Well, there’s no reason why the state of the NFS server can’t be replicated over to the second controller. I know other solutions do this. I’ve read the sparse information that is publicly available and it seems that the VNXe3200 only supports this kind of availability with SMB 3.0 since that stores certain state information in the filesystem (so it’s more of an SMB 3.0 feature than a EMC one), however I haven’t gotten official confirmation of this.
OTOH, apart from locking NFS is pretty much stateless.. I’m even sure if a non-graceful failover would even impact clients (in my case Linux) that much. Something I could definitely investigate.
I have connected emc’s to storage through two switches.
I have two cables running from each switch to the emc.
The hosts have links to each of the switch.
this way if I disconnect one of the link from EMC to switches, the host should have path to emc through the other switch. I should see a hitless failover right? But I see that the hosts cannot access LUNs for at least 30-40 seconds.
Do you need mutlpath software to avoid this? or does it come by default in 3.1.1.4823793
you should also have each of the SAN SP’s wired to each of the switches.
So while you will have one cable per host going to each of the san switches, you should have a total of at least 4 cables from the san to the switches. one cable from SPA to Switch A and one to switch B, and one cable from SPB to Switch B and one to A
this way the host can still access LUN’s even if a switch fails, without trespassing the LUN.
If you only have one cable the lun will need to trespass but that should be quicker than 30 seconds… do you have a vnxe3200 or is it a 3100, 3150, or 3300 ?
So you think this behaviour is not due to having power path?
even though we have two wires connecting from HP hosts to each switch, the Vcenter shows the following Multipath Status:
” Partial/ NO Redundancy”
we have vnxe3200.
I agree we should have two cables running from each SP to each switch. However we have only one 10G cable to spare, so if we had to have another one it would have to be 1G cable.
So then it would be a mix of 1 10G cable and 1 1 G cable from each SP to switch.
However does the multi path get selected by the Vcentre , or by the EMC?
The time of recovery is definitely more than 30 secs
path selection is made by VMware based on the paths that it can see. Power Path will do path selection if you have it installed, but for vmware the advantage is near zero if you have a single workload on the san.
I think the failover time is because you dont have it cabled properly, that is also why it says partial / no redundancy… have to have it cabled like i stated before in order to get that status message to change.
thanks..
will a 10G and another 1G cable still do the job? we do not have 2 10Gigs to connect to each SP?
Hi Justin,
Have you tested the failover of SP when VNX3200 acts as an NFS server?
eg. in the following scenario
a. NAS server is in SPA, and reboot SPA.
b. NAS server is in SPB, and reboot SPB.
Thanks
NFS services function just like the would in a VNX … there is a failover process I have not tested to see how long it is, as i no longer have the loner unit from EMC
Is NFS4 with sw 3.1.1.5803064 supported on the vnxe3200?
Thanks.
We have an EMC VNXe3200 configured with dual iSCSI ports (2 and 4 on each SP).
We are running Windows Server 2012 R2 on HP DL360 servers with 2 NIC ports setup for iSCSI.
Our iSCSI traffic is completely separate from our network LAN traffic.
I have configured MPIO on each Windows Server 2012 R2 server and confirmed there are at least two paths to the SAN.
When one of the SPs reboots on the VNXe3200, the servers end up going offline for 10 to 15 minutes.
I am looking for ways to improve my troubleshooting to figure out why I am losing connections when multiple paths are configured.
Previously I worked with Fiber Channel – which just works. iSCSI is becoming the death of me!
Thanks for any direction you can point me to!
Dan J
It sounds to me like the build in multipathing software isn’t switching to the other paths fast enough.
You could get a demo of PowerPath from EMC and try that out… it should switch paths a little faster that the native stuff.
Check out this document… its old but still applies https://www.emc.com/collateral/analyst-reports/11-10-00-esg-lab-validation-emc-powerpath.pdf
Thanks. I am checking with my EMC vendor now about pricing.
I also found a set of articles at this blogpost:
https://blogs.technet.microsoft.com/askpfeplat/2013/03/10/windows-server-2012-hyper-v-best-practices-in-easy-checklist-form/
I am planning to work my way through that as well.
Dan J