One of the things I’ve always looked for was a way to load test and benchmark some of the things I build. In the past I have used tools that will do IOps tests on storage arrays but for testing the entire infrastructure the best thing to use is a real workload. The problem with using a real workload is that it’s hard to find a business owner that is willing to be the guinea pig :). Sure I could setup some SQL benchmark VM’s and some Exchange benchmark VM’s… but honestly I find that way to complex for a few hours of testing.
However, if you have VMware vSphere then you also have access to the VMware Big Data Extensions “product”, I will just use BDE for short. If you haven’t heard of BDE its probably because you aren’t using Hadoop… yet. Basically BDE is just an orchestration product so that you can easily deploy Hadoop clusters. So instead of spending days setting up all the different components of Hadoop, you simply deploy an OVA file that contains an management server and a CentOS6 template vm.

After deploying the vApp into your vSphere environment you register it with the new VMware vSphere web interface and let the fun begin. From this interface you can define which datastores your Hadoop clusters can live on as well as deploy, delete, scale out, and scale up your Hadoop clusters. Oh and you can also check on some of the web interfaces of the Hadoop services.
OK, before you start saying that you don’t know anything about Hadoop let me tell you about the second part of the awesomeness.
Intel released a project called HiBench; HiBench is designed to benchmark a Hadoop cluster and can be used with almost NO Hadoop knowledge. As long as you understand how to use a few linux commands, you can be off and running in almost no time. (There is only one file that MUST be configured) The reason for this is that it assumes that you already have your Hadoop cluster configured the way you want it and all it needs to do is leverage the existing cluster to run its benchmarks. Luckily for me (and you other non Hadoop people), VMware BDE takes care of all of the Hadoop configuration for us! WIN!
So why am I using this combo?
Well to be perfectly honest I am using this combination of products because it can scale out and scale up very easly (more on this later), and with as powerful as hardware is getting these days it is hard to throw a somewhat realistic workload at things and get meaningful results. However with Hadoop and HiBench I can have as much test data automatically generates as I want, then I can scale out my worker nodes to take advantage of every single Ghz of power on the compute side of my infrastructure. This will ensure that not only can I leverage all cores of all ESX hosts… I can then also leverage all storage paths and networking paths as well. This means that whenever I get to test an AFA (All Flash Array) I can use this test without any further config… assuming I have enough CPU resources to support enough Hadoop worker nodes in order to drive enough IO.
If I wanted to do this same thing with Exchange or SQL I would need to simulate hundreds if not thousands of users or transactions in order to drive enough CPU to flood my storage or network. With Hadoop I can just tell it to sort a 500GB or 500TB dataset. Then if I notice there is some unused CPU capacity I simply tell VMware BDE to scale out the number of worker VM’s until all sorts of vCenter alarms go off. Then all I need to do is sit back and wait to see how long it takes for the processing to finish.
The main driver for investigating Hadoop as a benchmark was because of the VNXe3200 that I have in my lab on loan from EMC. Normally with 1GB iSCSI and a small number of SAS drives I am able to benchmark an SMB storage array pretty easily… one or two ESX hosts running a couple of Windows VM’s and an IOps measuring tool and Im good to go. But the 3200, with all of its SSD drives and MCx firmware goodness I wanted to make sure I was pushing it to its limit.
Lastly a benchmark is only good if you have things to compare it to, so the fact that both VMware’s BDE is basically free, and Intel’s HiBench is opensource; it means that anyone could download the bits and run this against there infrastructure. (Just as a note… if you do run this… it will grind anything else on the hardware to a halt… you’ve been warned).
So how do I do it?
If you dont have the VMware Big Data Extensions OVA file download it from here first http://www.vmware.com/products/vsphere/features/big-data
Then deploy the OVA to your vSphere infrastructure to be tested, and follow the installation guide on how to register BDE with the vSphere Web Client.
Next Make sure that you have datastores assigned to “Shared” and “Local” storage resources. Personally I dont use Local storage at all, but I have found that I can assign one SAN’s datastores to Local, and another SAN’s to Shared so that I can test two Arrays at the same time.

You will also have to set a VMware port group in the Networks Inventory list as well so that it knows where to put your Hadoop VM’s
Then the last thing to do is to create a Hadoop Cluster.
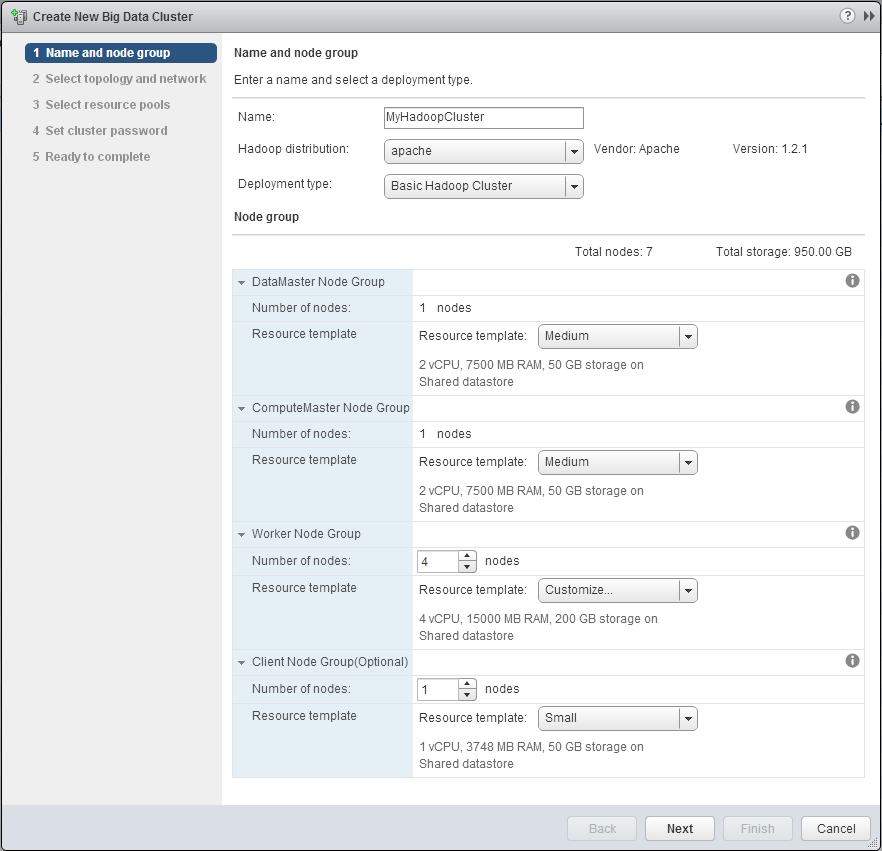
To do that click on the Big Data Clusters Item in the list on the left. Then in the main area of the web client you will see a small yallow cluster of servers with a green plus sign, click that icon to create a new Big Data Cluster, this will start the cluster wizard. On this page you assign your cluster a name, then pick the number of nodes that it will have. You can ignore the distribution and deployment type for this benchmark as we aren’t doing anything fancy.
Depending on the hardware you are working with you may need to change the node types to Small, Medium, Large, or custom. Pay attention to the Shared or Local datastore setting. If you assigned your datastores to one or the other, If you need to change the type there is a trick that I picked up after deploying a couple clusters.
First select the size of node you want (Small Medium or Large), then click the drop down again and select Customize. This will keep the base settings of Small, Medium, or Large, but allow you to further tweak the settings (like the datastore type).
Next you will need to assign the network and topology type. I have been picking “NONE” for the topology type, I think (Not sure though) that the topology type helps BDE determine if it needs to configure the HDFS nodes to replicate the HDFS data or not. The network setting is pretty straight forward.
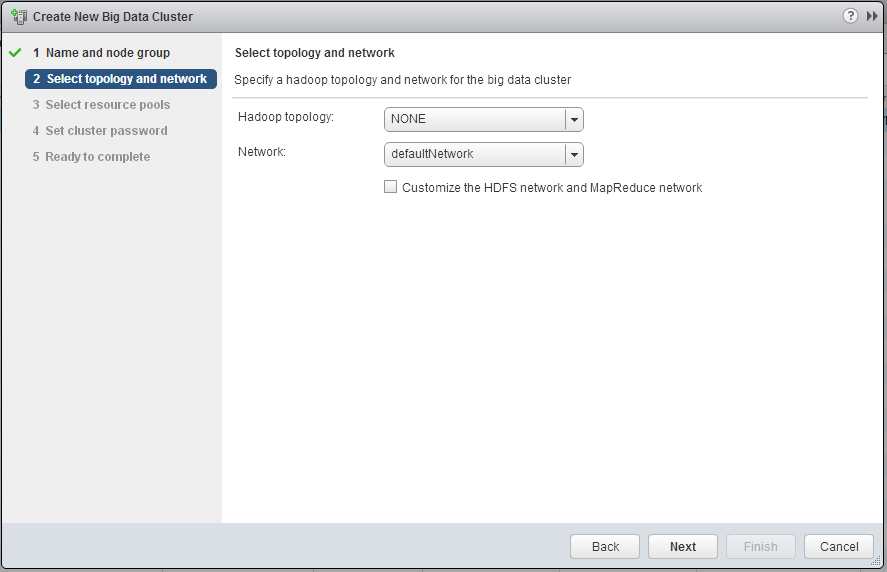
Step 3 is where you select which cluster of Compute resources you want to test. The Cluster to be tested does not need to be the same one that is hosting the BDE vApp.
Step 4 is where you can specify a password for the cluster (the username is serengeti, or you can use root)
The last page just gives you the typical VMware summary page and has you click Finish, when you do the BDE Management VM will work with vCenter server to clone the template VM as many times as needed for your cluster, and then run Chef scripts against them to install and configure the proper Hadoop components. They whole process only takes a few minutes.
Once the cluster is finished provisioning and is ready for use it will look like this in the cluster list.
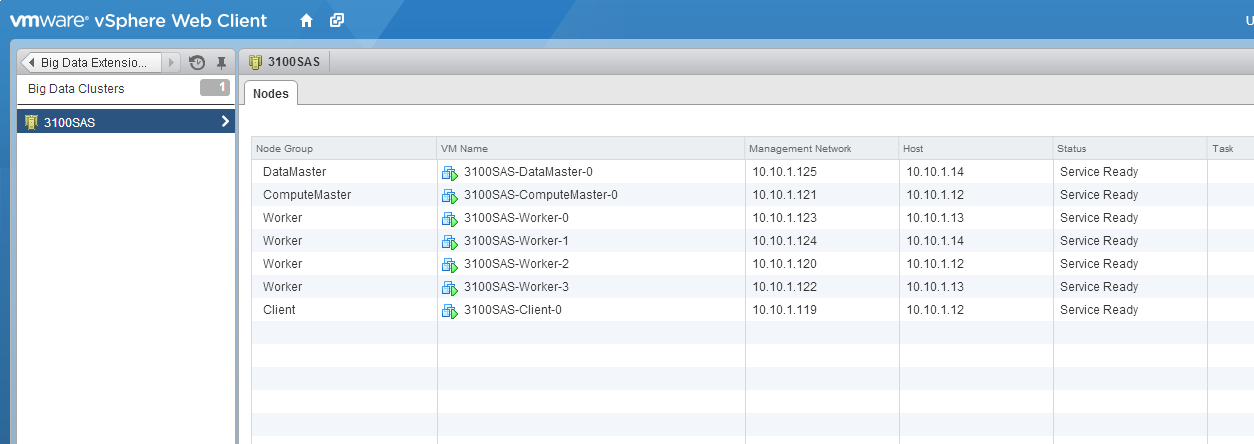
Once you are this far we are ready to login to the Client node and download HiBench.
Use something like Putty to connect via SSH to the IP address listed for the Client node, in my cluster its 10.10.1.119. Use serengeti as the username and the password you specified in the wizard.
Next download Intel HiBench to your client node. Use the following commands to download HiBench and install Zip in order to unzip the file
wget https://codeload.github.com/intel-hadoop/HiBench/zip/master
mv master hibench.zip
unzip hibench.zip
This will leave you with an intel-hibench-* folder, I didnt like typing that every time so I used a move command to make it more friendly.
mv intel-hibench<tab key to auto complete> hibench
You should just have a hibench folder now.
Next we can edit the main configuration file that tells HiBench where Hadoop is installed. For VMware Big Data Extensions’ default apache distro this path is /usr/lib/hadoop
To edit the config file change to the config directory and use VI
cd hibench/bin
vi hibench-config.sh
Once inside of VI scoll down until you see the line containing “export HADOOP_HOME=” … this is the variable where we want to replace the existing directory with the one mentioned above. To do that position the cursor over the existing directory path and press “x” or the Delete key until you have removed it. Then press “i” to insert the new path. Type /usr/lib/hadoop. Then press “Escape” then “:” and then “wq” and press enter. This will tell VI that you want to “write” and “quit”.
Time to run some tests!
At this point you are good to go. However you should probably read the documentation to see what each test does. In all there are nine different tests that HiBench can preform, it can also run them all in batch fashion or you can manually execute each one. For the testing that I am currently working on I an using the terasort benchmark, as it seems to give a good amount of read and write IO while also driving lots of CPU cycles too.
One last note on Terasort… by default the hibench config for terasort is set to generate a 1 terabyte dataset. Make sure that when you created your cluster you picked datanodes with enough storage in them to support however much you want. Personally for me I changed the dataset size to 200GB, you can do that by using VI to edit the hibench/terasort/configure.sh file and change DATASIZE= to 2000000000 instead of 10000000000.
Then to actually run the tests use the following commands.
cd hibench/terasort/bin
./prepare.sh (this will prepare the data for the benchmark)
./run.sh (this is actually the test)
Of course you will want to record the start time and the finish time so you can see how it did.
Stay tuned for posts on how the VNXe3200 compares to a VNXe3100 as well as to local storage.
Oh, also if you want to know what each test goes, go to the HiBench GitHub page and view the readme file as it has details on what each test does.
![]()

