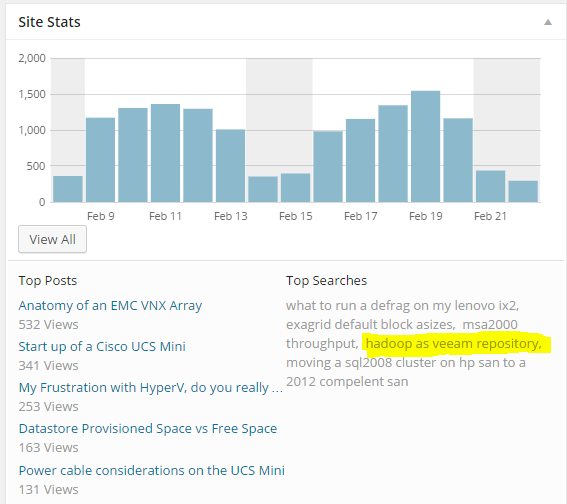
I was looking at the internet search queries that bring some of the readers to my site the other day when I found one that was rather interesting. It was simply “hadoop as veeam repository”.
Now, before I get too far into how to make this actually happen let me just point out a few things. First off, if you haven’t been to the disclaimer page in a while now may be a great time to check that out 🙂 . Second, I don’t think anyone has ever done this before… production or test… so if you are the person who was searching for this article: make sure to test this more thoroughly than I have before betting your job on this.
Why?
After thinking about this for a while, the concept seems really genius. The idea behind Hadoop is that you take a bunch of cheap computers with locally attached disks (typically large NLSAS or SATA drives), interconnect them with a high speed network, and use them to store a CRAP LOAD of data. Facebook for example reported that they had 21 PetaBytes in a single cluster… in 2010. So if you have all of that storage, and its cost per GB is pretty cheap, why not use some of it to store backups? After all if the Hadoop admin is managing 21PB of storage do you think he would ever miss a few hundred TB?
Reality
I have good news, bad news and some more good news.
First a little good news, Hadoop has a function called NFS Gateway that allows NFS access directly into and out of the Hadoop file system (HDFS). The idea was that uploading data into HDFS for processing by Hadoop and its different languages was a huge pain in the ass. So to make it easier they created an NFS Gateway function to make it as simple as a linux file copy.
Now for some bad news. After checking out most of the Hadoop distributions I have used before, as well as the Apache Hadoop page, I found that HDFS and therefore the NFS Gateway do not support random writes. This is probably going to be a show stopper in 99% of the Hadoop deployments. Basically the reason this is going to make doing backups to HDFS (the underlying file system of Hadoop) impossible, is because HDFS stores data as objects, not as blocks. So if an object needs to be updated with just some data (not all of the data in the object) it basically has to read the entire object into a cache, update it, then write it back out to HDFS. I will do some more testing in this area to see if that is truly a show stopper, but my guess is it will be… If you are a Hadoop Guru and have more information please let me know… would love to be wrong on this part :).
Now for a little more good news.
There is one distribution that I found that doesnt suffer from the short comings of HDFS. Enter MAPR. The MAPR hadoop distribution removes the standard HDFS file system in favor of its own MAPR-FS file system. Because of this they claim it will support pretty much anything you can throw at it in terms of read/write patterns. In my testing it was also the easiest to get working because it came with the NFS Gateway service running out of the box!
Making it work
I don’t want to ruin the ending, but I know the first part of this article is pretty wordy, so let me start by just saying I was able to get Veeam to do backups to the MAPR Hadoop sandbox that I setup. So there is no reason (as long as you’re running the MAPR distro) that this should not work on a larger scale.
The Architecture
For Veeam to write to any linux folder it has to have an agent on that linux machine. That agent can become CPU/Memory intensive if you are pushing enough data through it. For that reason I choose to separate out that role for a dedicated server.
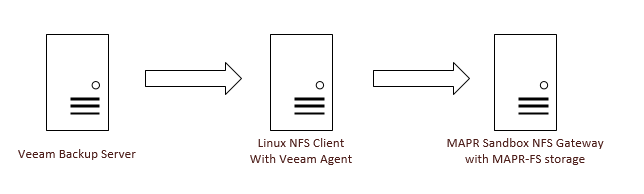
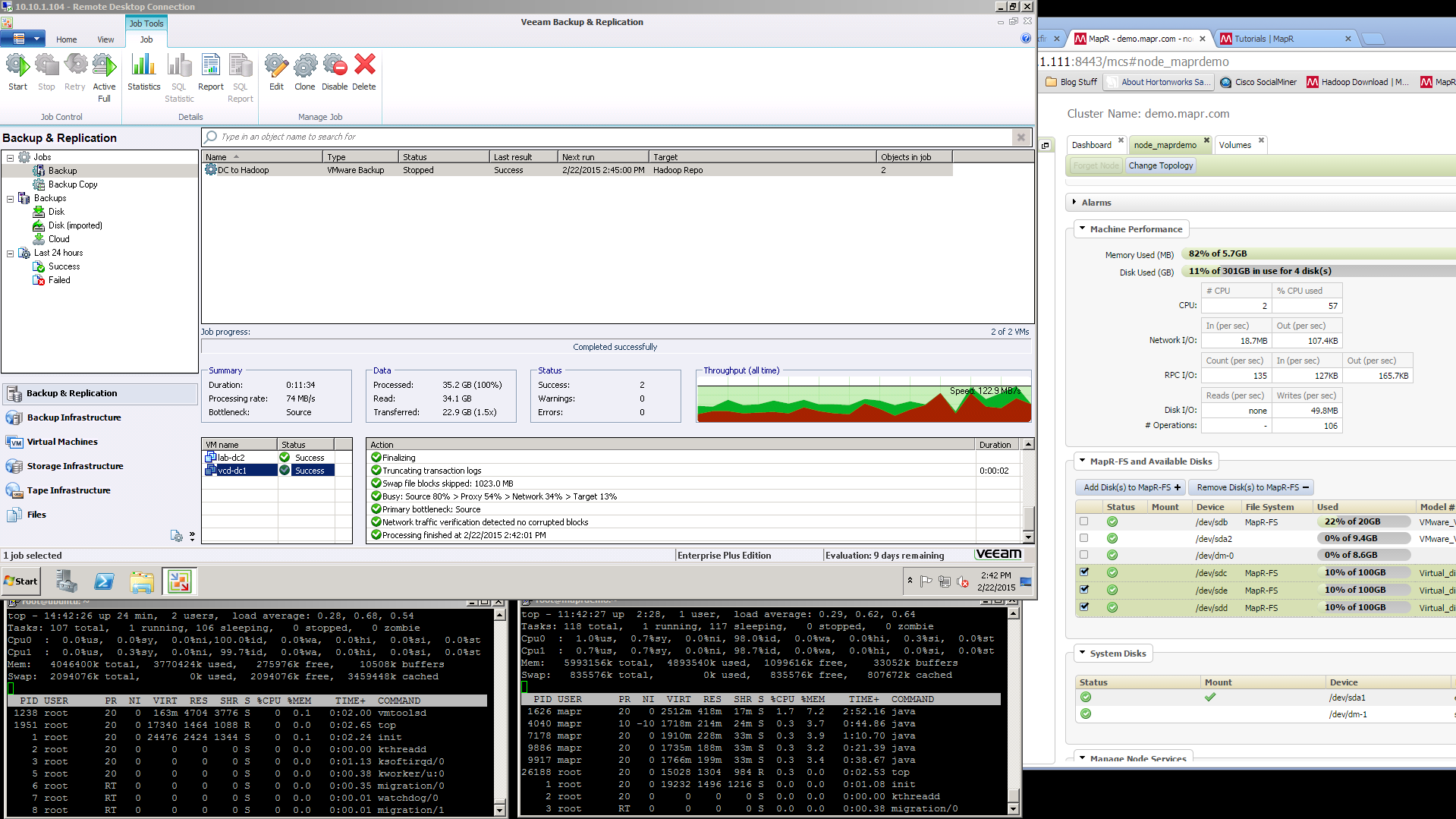
I will explain this in reverse order of the data flow. The backup data will rest on the MAPR Sandbox VM, that VM will also be the NFS Gateway Server. It will receive data from the Linux NFS Client in the middle. The NFS client VM basically uses native NFS protocols to mount the share from the MAPR NFS Gateway, and from this middle point on up it will appear as a normal linux directory. On the Veeam server we do not need to enter any data about the MAPR cluster, instead we only need to know the IP address of the Linux NFS Client. With that information we create a Linux Server object in Veeam and then create a backup repository, making sure to select the NFS mounted directory.
Again the reason I did it this way was so that the Veeam services did not overload the MAPR sandbox VM. I suppose I could have cranked up the CPU and memory on that VM, but this way seemed to make more sense because in a real world scenario you would have many MAPR servers providing disk space and NFS gatway services and if one of them died you would just toss that node. Remember hadoop nodes are like donkeys: we want their heavy lifting capability for the hadoop farm, but we don’t care about them enough to give them names. So if a node dies we just toss it from the cluster and add a new one later, because of that mentality we wouldn’t want our NFS client running on one of them.
Backup Speed
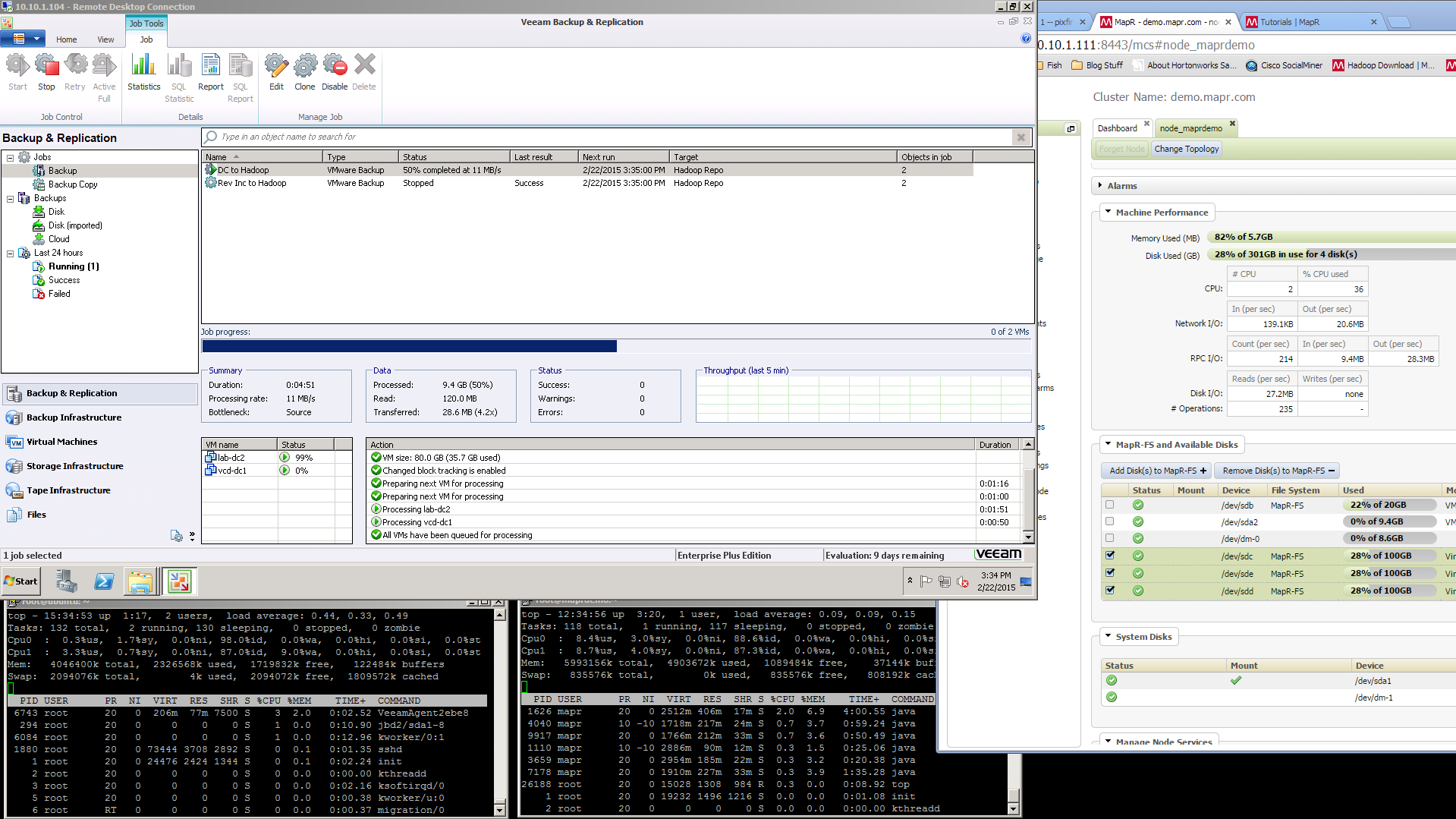
Also I should note that I was ableto achieve about 60MB/s during the backups, which doesnt seem like a lot, but remember this is a lab environment, and the VM’s being backed up were on a 2 disk RAID 1 (they are 600GB 15k SAS drives). Because all VM’s involved were on the same VMware ESXi host, network was line rate at 1Gbps, I didnt get a chance to test at 10Gbps, but my storage wouldnt support it anyhow. The MAPR VM was located on an iSCSI attached VNXe3200 with 200GB of FAST Cache and 1.8TB of SAS RAID 5 disk.
Restore Speed
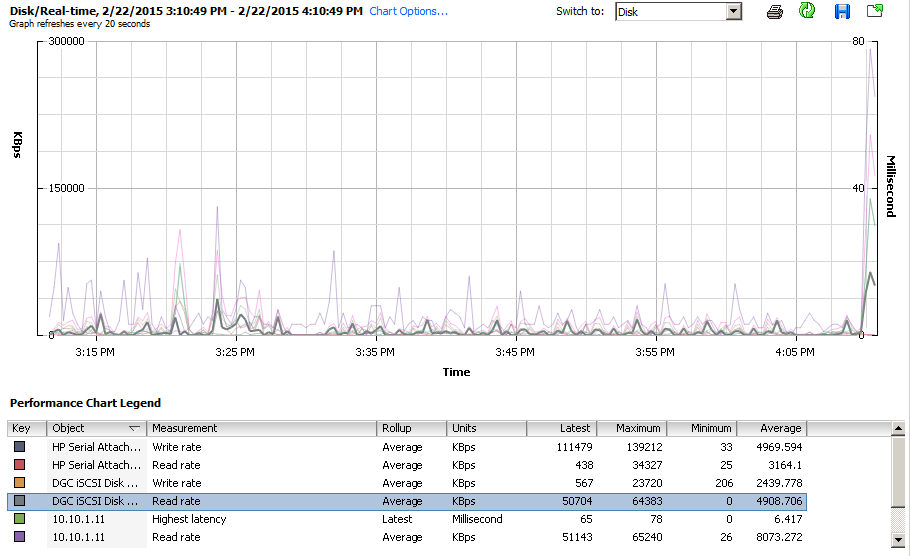
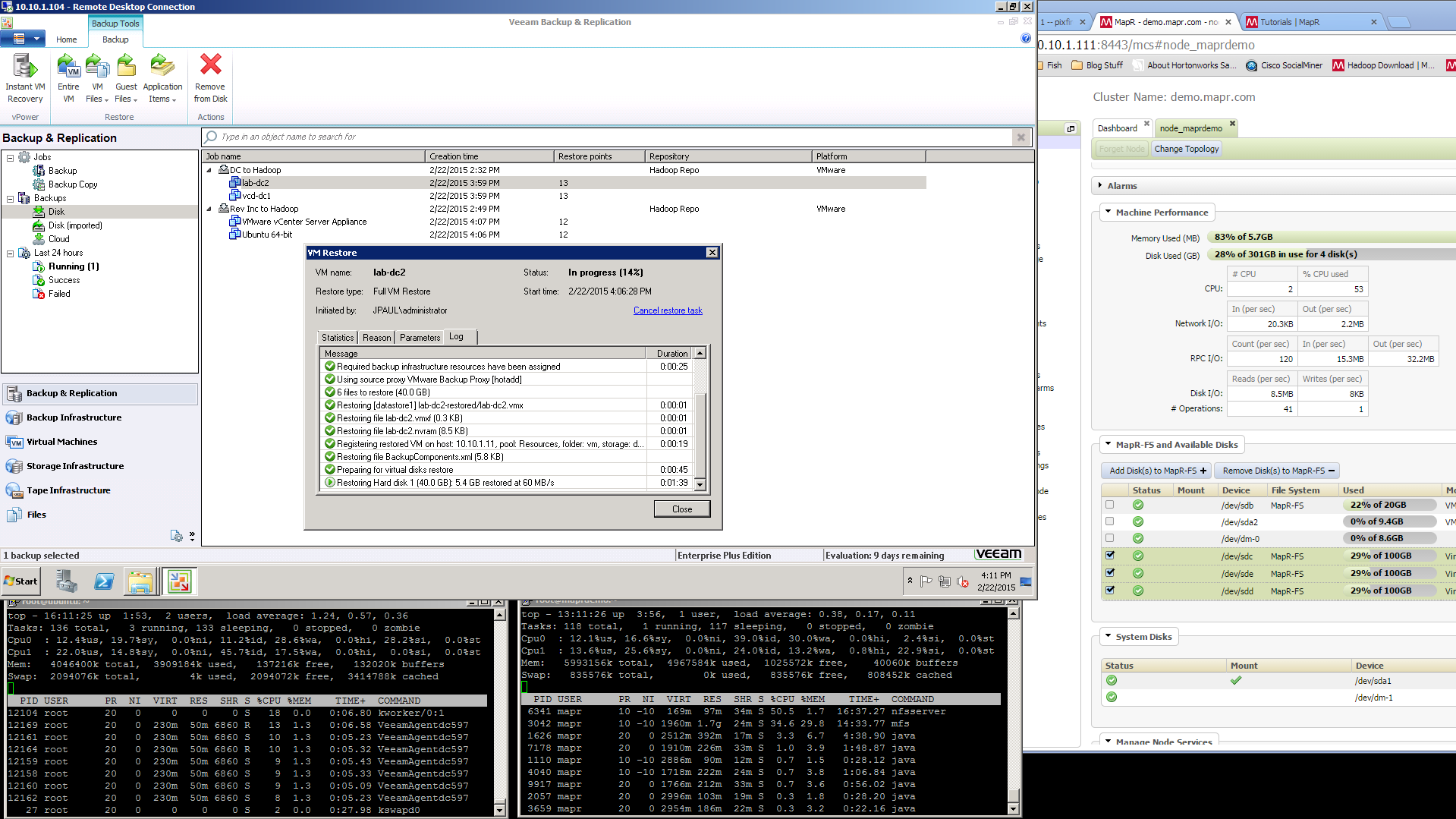
The restore speeds on the VM that I tested were just as fast, if not faster, than they are from a local windows based Veeam repository. So even though the data is flowing through many layers it isn’t slowed down much. I think that if I were able to run this against a large MAPR-FS farm the speeds would be even more impressive. See the screenshots below for actual speeds, but It took about 5 minutes to restore a VM with 9.3GB of actual data on it.
Take away
This is certainly something that I want to keep my eye on. I think that there will be very few people who find this article useful right now, many will probably find it interesting but because almost all Hadoop distros dont fully support random writes I think it will be a while before many could take advantage. (I’m not sure what the user base size of Hadoop as a whole is compared to MAPR user base size)
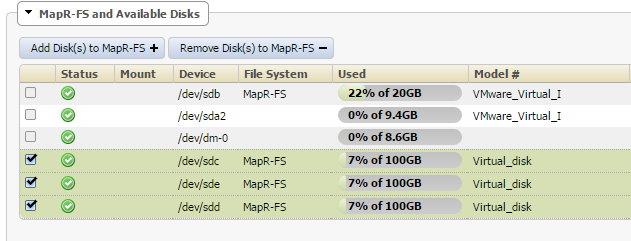
Screenshots
Here are some screenshots of the process. Remember if you click on them they will enlarge.
![]()




Great post as usual Justin. FYI, the NFS gateway on MapR is much different than the Apache one. (ie. used by HDP)
We had a client that went from MapR to HDP (mostly because the price was 1/10th..) but quickly found out the NFS gateway would not work as they were using on MapR. They had to rewrite all shell scripts to use “hadoop fs” commands vs doing things right on the NFS mount. Also, often times the gateway hung and had to be restarted.
We’ve had clients ask us about using HDFS for backups and it just didn’t make a lot of sense to us. The big reasons why people turn to Hadoop is not only for storage but for analysis on that data. It would seem there are better products out there (Gluster?) that would be much easier to work with that allow the combination of cheap servers to act has low cost massive storage.
-Tom
Hey Tom!
Thanks for your insight, as one in the business of storing data for people and doing Hadoop, its great to get your feedback!
I agree that I don’t know how feasible this would be, but if you had the MAPR stuff already in place it might be worth a POC 🙂