I tried a couple of times to get Hadoop installed on Ubuntu from the group up, and while there are a bunch of how to guides out there, many of them are designed for older versions of Hadoop or Ubuntu. In the end each time I tried to get it going something would get in the way. So I figured since I do a little work with VMware and virtual machines, why not see if there was a prebuild virtual appliance out there. Sure enough I found several, and while Hortonworks was not the first one I tried, it was the first one I would recommend you try.
Why Hortonworks
So the way I like to learn is by doing, and without knowledge of how to program in MapReduce, Pig, or one of the other Hadoop related languages, it makes it hard to start “doing”. Enter Hortonworks Sandbox, a fully configured virtual appliance that has everything you need to get started and more. By more I mean that it comes with a bunch of tutorials to get you started. Everything from how to use their web interface, to how to upload data into HDFS, to running jobs in a variety of the supported languages.
Getting started
To get started you simply download the virtual appliance from the Hortonworks website. The file is about 2GB in size and is an OVA file, meaning that it is ready for direct importation to vSphere or VMware Workstation without much effort. After importing you simply power the VM on and it will boot up and grab a DHCP address. Once you have that you are all set. Head over to your favorite web browser and enter the IP address shown on the virtual machine’s console.
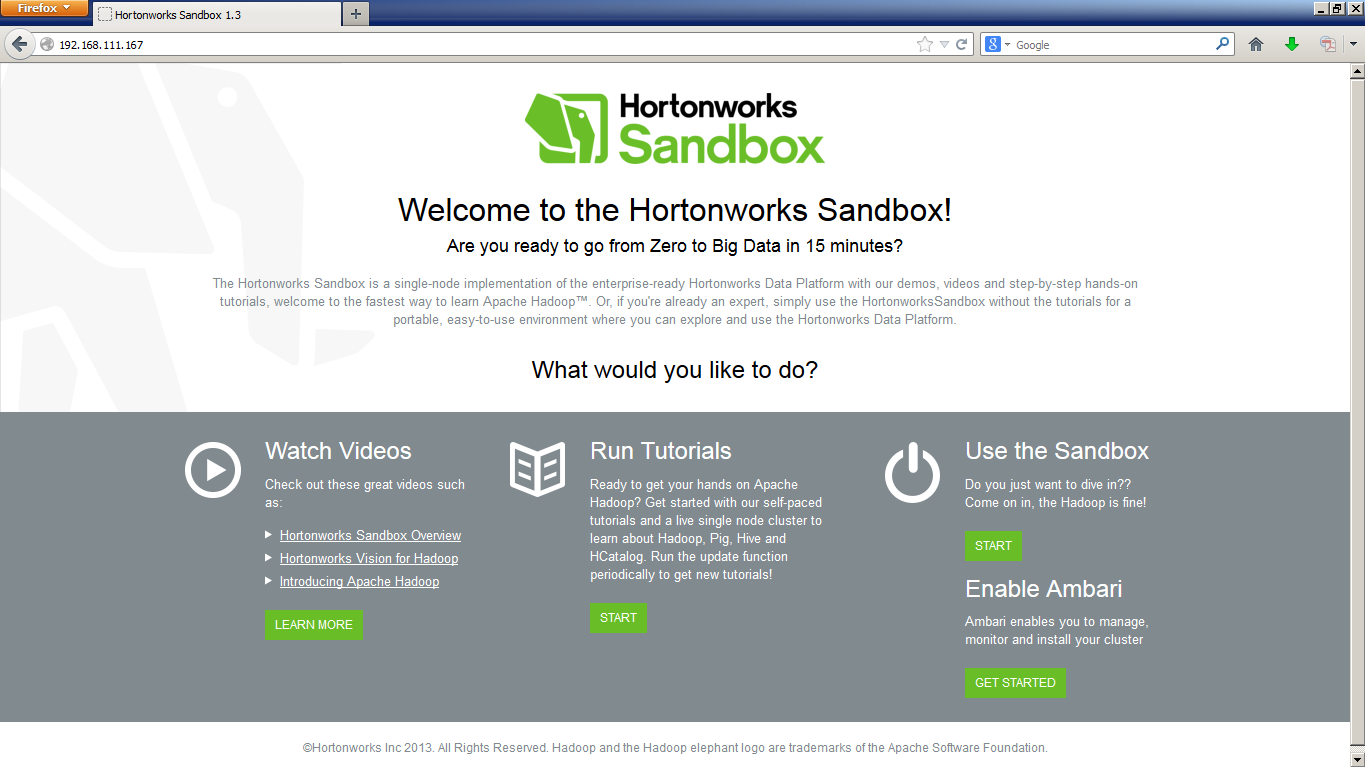
There are four sections to the sandbox homepage, and area where you can view videos and get an overview of Hadoop and Hortonworks, then in the middle there is the tutorial section, and finally on the right you have a section to start using the sandbox and instructions on enabling Ambari (which I’m under the impression is for when you want to start building out your Hadoop environment larger than just one node).
The Tutorials

So this is the section I have spent most of my time in so far, in one afternoon I was able to get through most of the tutorials and have a much better understand of the different languages available for Hadoop.
Once you click on START you are taken to a split browser where on the right you find your work area, which looks identical to the production Hortonworks Sandbox, as well as a panel on the left which contains all of the tutorials. I must say I really like this layout as you aren’t forces to have two monitors, or to jump back and forth between browser windows.
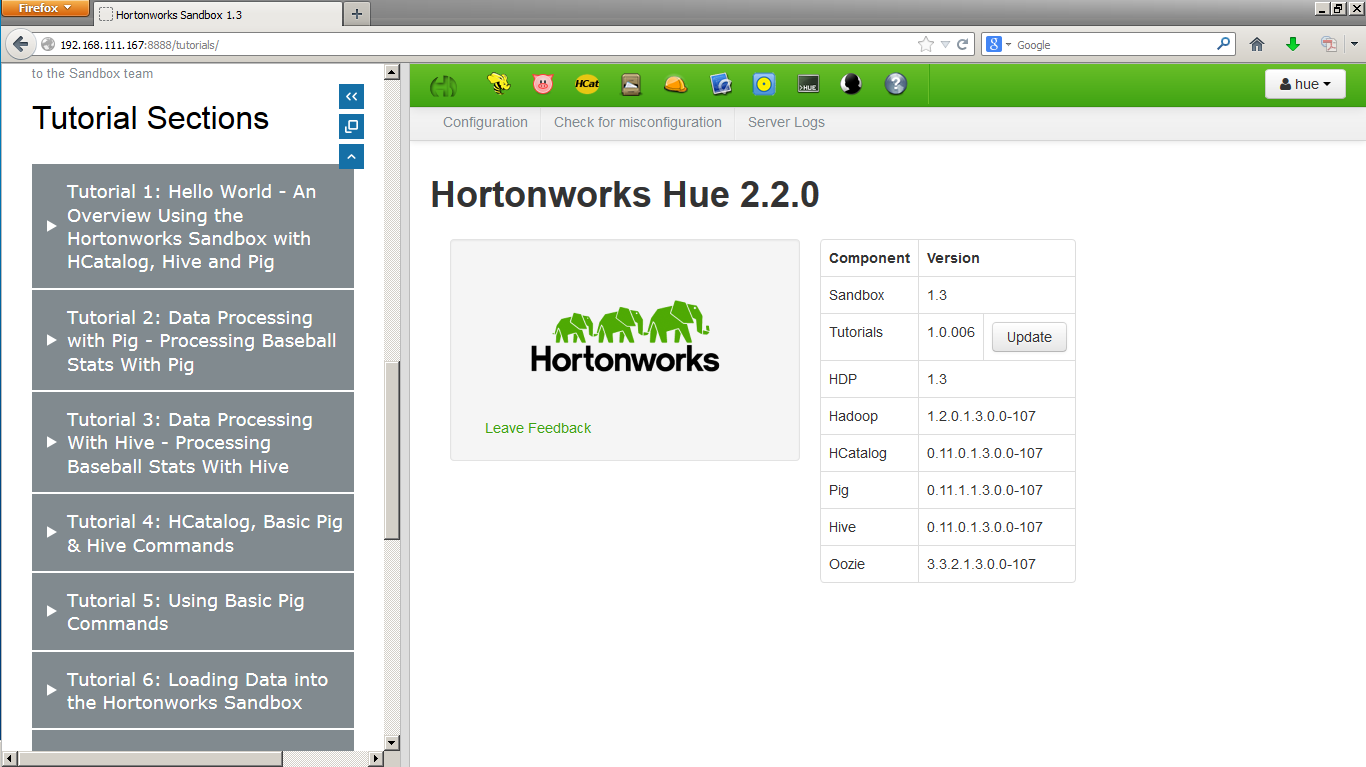
As you can see the tutorials take you through step by step, with a bunch of hand holding…. perfect for someone with no prior experience with Hadoop, but by the end of the tutorials (I believe there are about a dozen at this time) you will find your self skipping sections that you have already picked up on because using Hadoop seems to be a fairly straightforward process when using one of the nice web-based GUI’s.
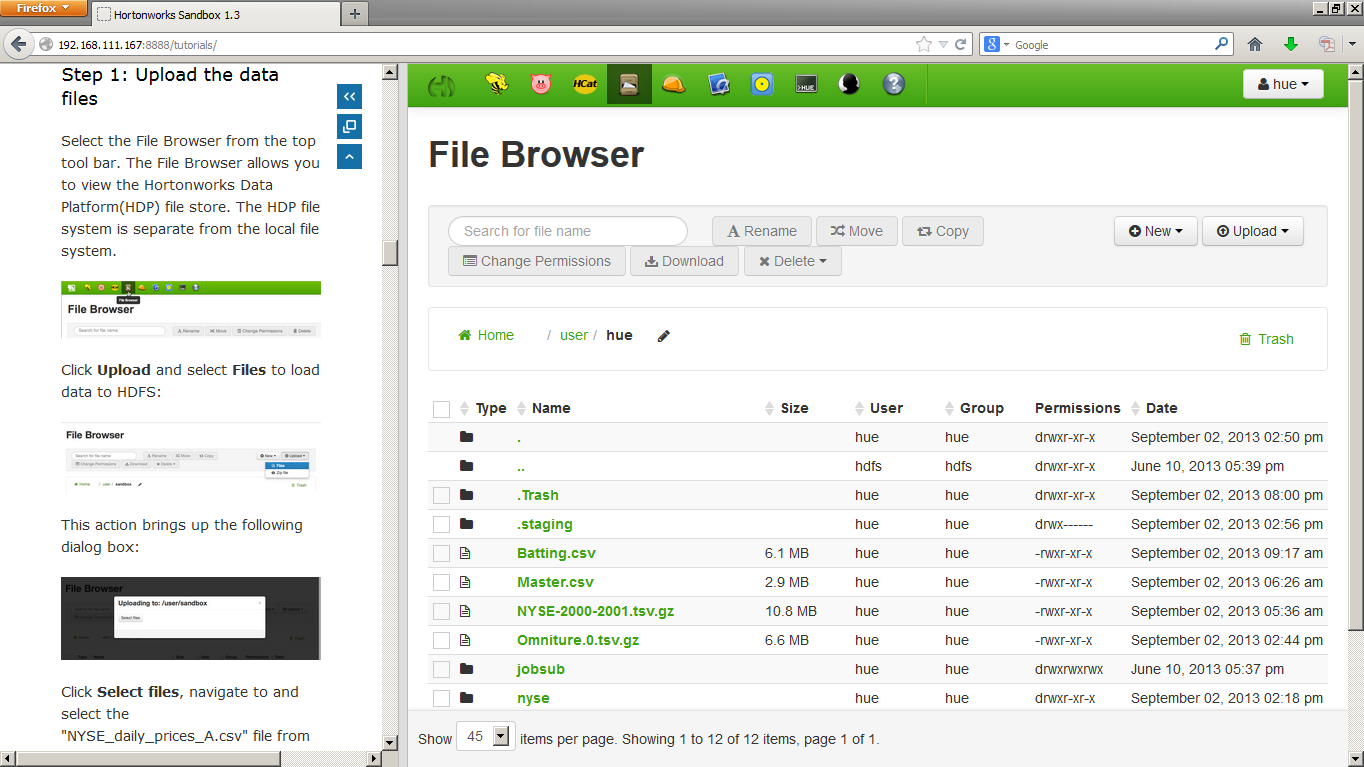
BYOD Time
No not bring your own device, this time I mean Bring Your Own Data…. once you have finished up all of the tutorials and are ready to try your hand on your own you can flip over to the real sandbox, which is really the exact same website, just without the tutorials on the left.
This area allows you a full browser window of the interface you used in the tutorials to get started with your one node Hadoop farm to start looking at your own datasets. Note: if you don’t have a dataset do some Googling, there are many datasets of various sizes on the web for free.
Once you are comfortable with Hortonworks and are ready to move to a multinode Hadoop farm, don’t fear… VMware’s Big Data Extensions already has support for Hortonworks 1.3 and you can use BDE to deploy a multinode cluster on VMware very easily (But that’s for another post).
![]()

I am using Hortonworks sandbox for hadoop …How do i debug java code in eclipse?
I am using Horton works sandbox for hadoop, But i am using eclipse on windows for the java code . and hortonworks sanbox installed in oracle virtual box. I created executable jar for that java code and then run in hortons. How do I debug the java code in eclipse?
no clue …