Zerto Long Term Retention
Zerto is known for its super low RPO and RTO objectives and its ability to “re-wind” your VM like a DVR would do to a movie. Those features require production class storage, and sometimes lots of it. So while you can keep a Zerto journal for up to 30 days, some customers want to keep a shorter journal, and others just wanted recovery points that go back farther than 30 days.
This is where Zerto’s LTR functionality comes in. Zerto LTR takes a Zerto journal checkpoint (which is stored on expensive SAN type storage) and makes a backup copy to another storage location.
in this post, I’ll show you how to setup that copy to the HPE Cloud Volumes Backup service.
HPE Cloud Volumes
HPE Cloud Volumes has several different services built into it, one of which is the Backup Volumes service.
The Backup Volumes service is accessible via HPE’s Catalyst protocol which Zerto integrated support for in version 7.5. This means HPE Cloud Volumes Backup works great as a Zerto Long Term Retention repository!
What makes HPE Cloud Volumes Backup different than buying an HPE StoreOnce appliance, or using the virtual storage appliance software, is that you do not need ANY* local storage to make it work.
I put an asterisk on “any” because you will want to run their secure client, which requires a small linux machine, but it is just a proxy service. No data is stored on the secure client machine.
The service is super easy to use!
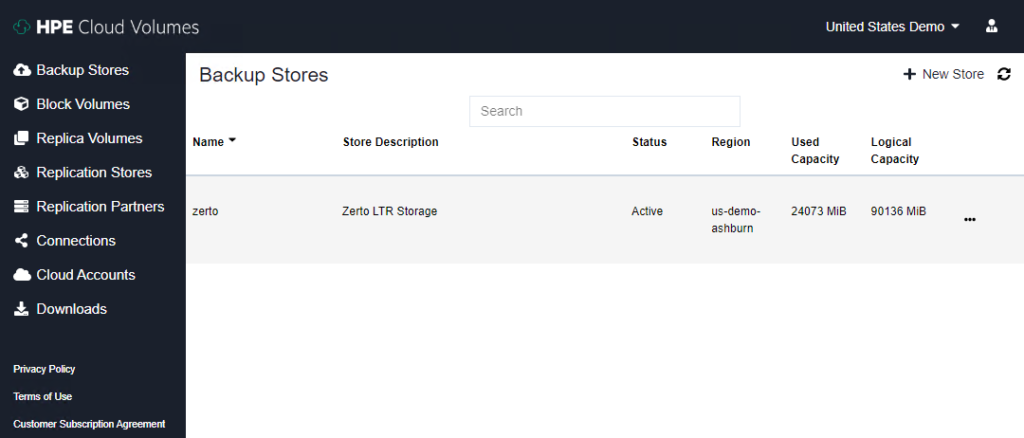
Creating the Backup Store
Once you are signed up and login you are presented with a sidebar with the various services in it. Right up at the top is the Backup service, that’s the one you want for Zerto LTR storage.
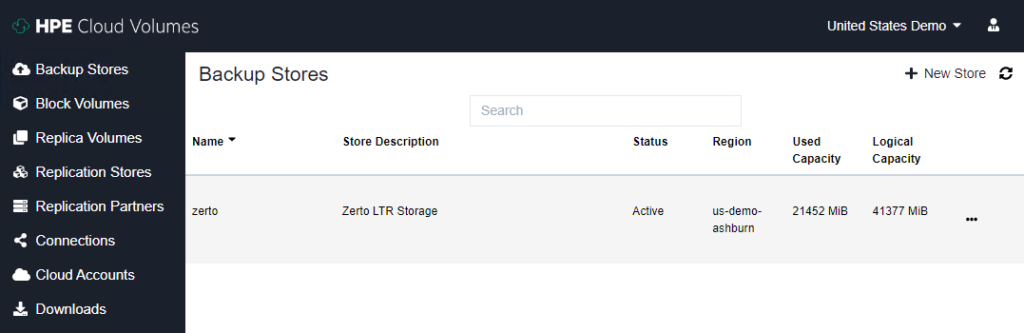
To create a new backup store, click “New Store” on the top right side of the Backup Stores dashboard.

There is a simple wizard that you will fill out. You need to enter a Store Name and pick a Datacenter region. Then click create store.
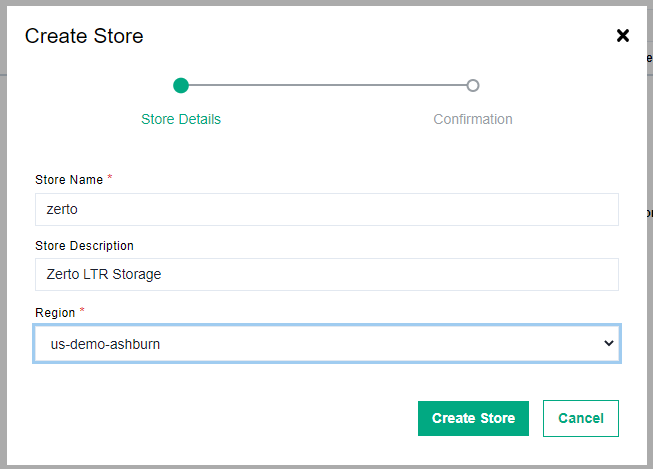
Once the store has been created you are presented with a page where you need to save the store password. You need to save the password before you close the wizard. Also make note of the username too.
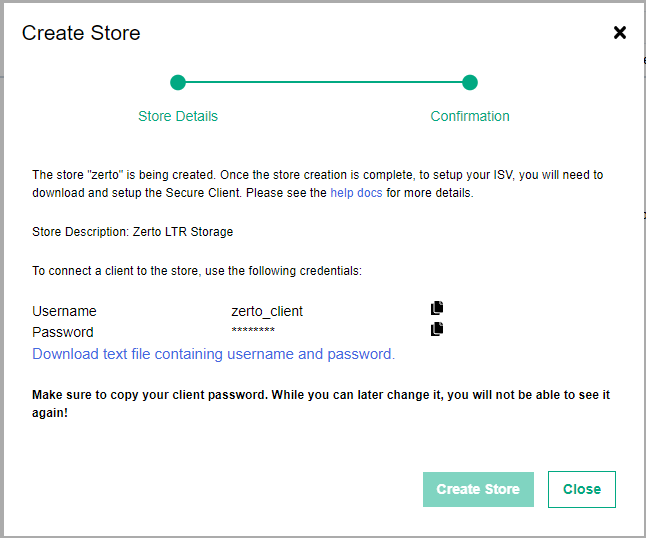
Now we can setup the secure client, which is the endpoint inside of our datacenter that Zerto will connect to.
Installing the secure client
Instead of sending raw Catalyst traffic over the internet, HPE has developed a secure client that acts as a proxy server for the Cloud Volumes Backup Store.
It is a lightweight linux binary that you can run on any Linux OS.
To download the client, click the three dots to the right of your new backup store and select “Download the Secure Client”.
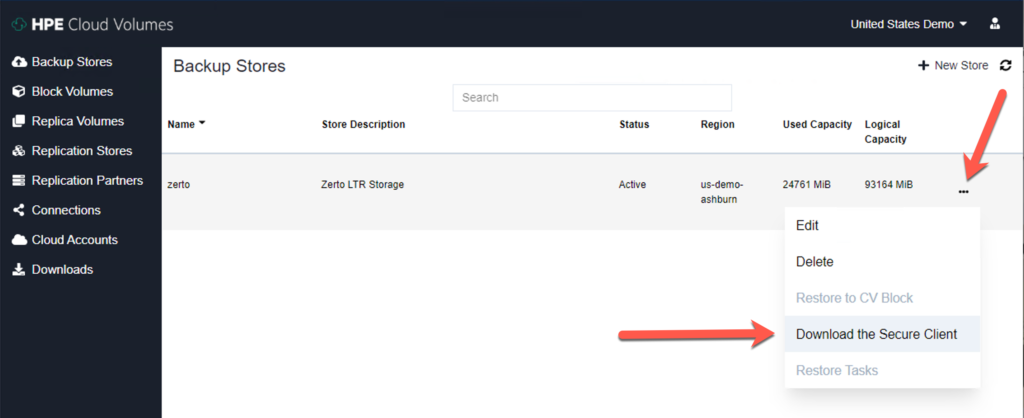
Transfer the client package to a Linux machine with something like sftp.
I won’t deep dive into setting up the Linux machine itself, but you will probably want to configure it with a static IP address at a minimum.
Inside of the secure client zip file there is a README.md file that explains how you should configure the Linux box so that the client starts at boot time as a service. For this lab test I choose to just extract the client and run it manually for testing purposes.
To run the client you can just type ./secure_client in the extracted folder.

Once it is running, you will see INFO messages once it starts proxying connections.
We are now ready to add the Cloud Backup Store to Zerto.
Adding a Zerto Repository
Once you have the local secure client running you are ready to add it as a Zerto LTR repository.
Log in to server’s ZVM page and navigate to the setup page from the left menu. Once you are in setup screen, look for the Repository tab.
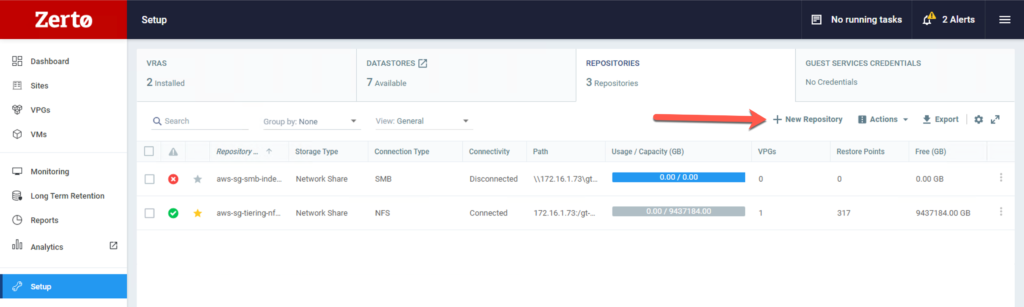
All of the details that you need for the repository come from the Cloud Volumes New Store wizard and your Linux secure client.
Username, Password, and Catalyst Store Name are from the Cloud Volumes Site.
Catalyst Server is the IP address of the secure client Linux machine that you setup locally on the same network as the ZVM and VRAs.
At the top of the Add Repo wizard, make sure to set the Storage Type to “HPE StoreOnce” and the Connection Type to “HPE StoreOnce Catalyst”. The default is NFS, which will not work with Cloud Volumes Backup.
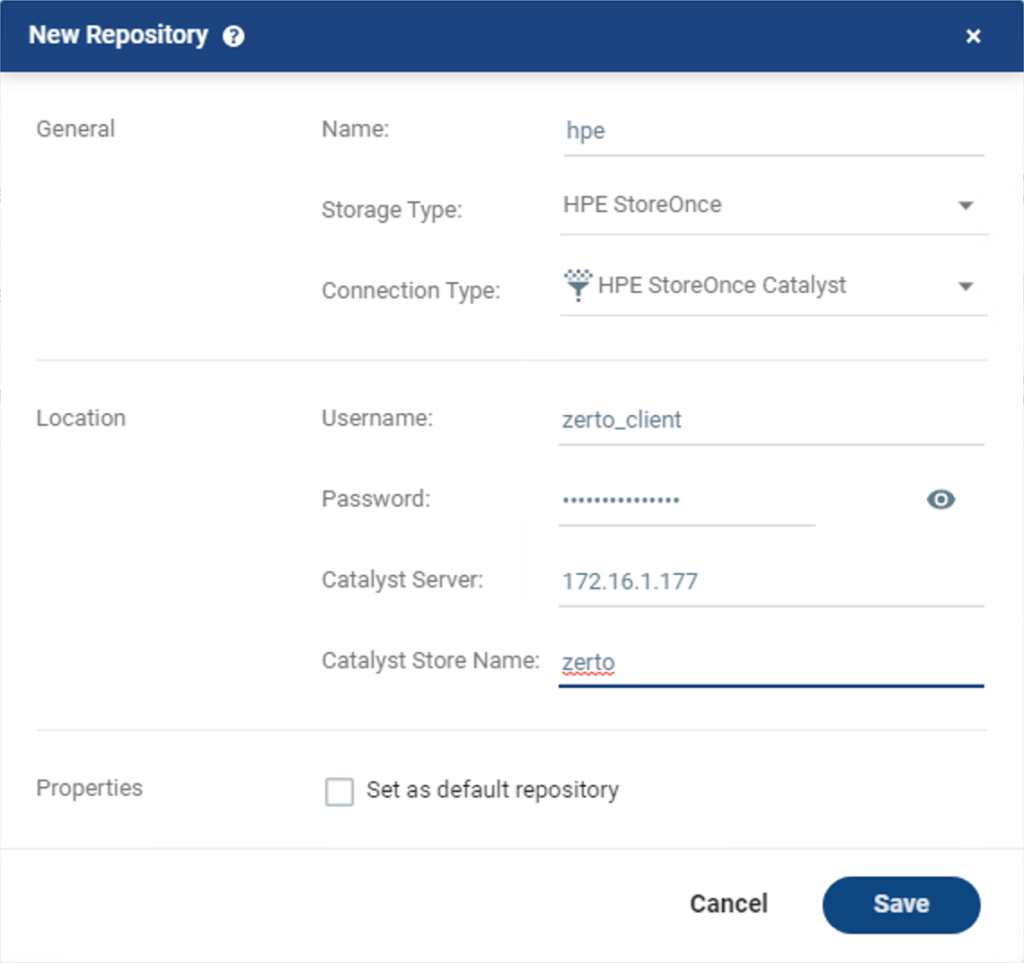
Once you have everything filled out, click Save. The repository should get added to the list in Zerto. If it does not, and you instead get an error message, my first recommendation would be to check the firewall on the Linux Secure client. I disabled the firewall on my machine, but you could also create firewall rules to allow the Catalyst ports to listen on the network.
Adding LTR settings to a VPG
Once your Repository is set up and added into Zerto you can add LTR retention settings to an existing or a new VPG.
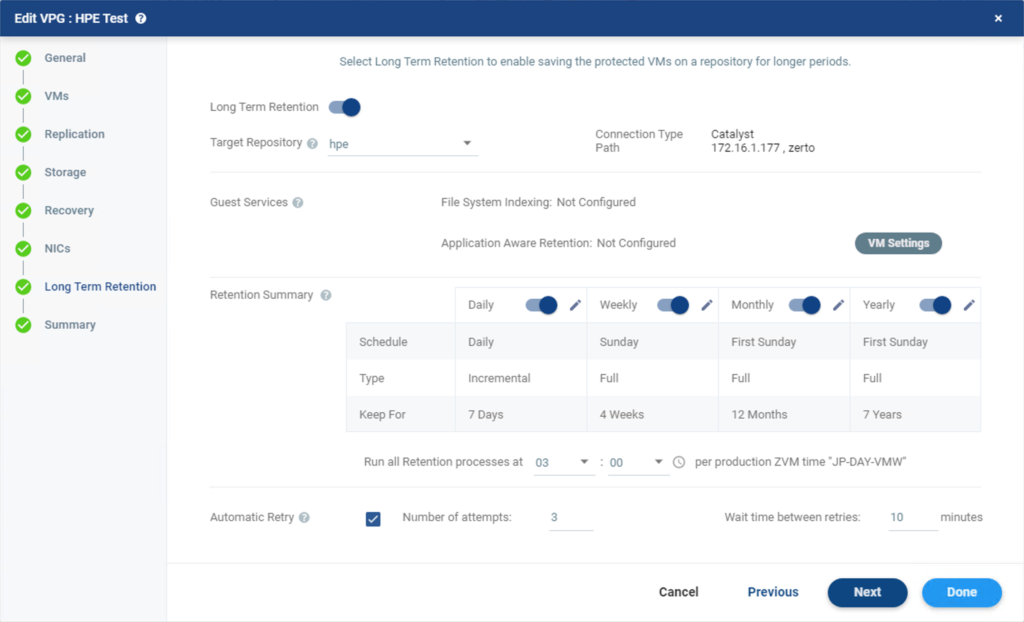
Make sure to select your recently added repository as the destination. Then click Done.
You can wait for 3 a.m. to roll around and the retention schedule to run automatically, or you can click on the three dots to the right of your VPG in the VPG list, then select “Run Retention Process” to trigger it manually.
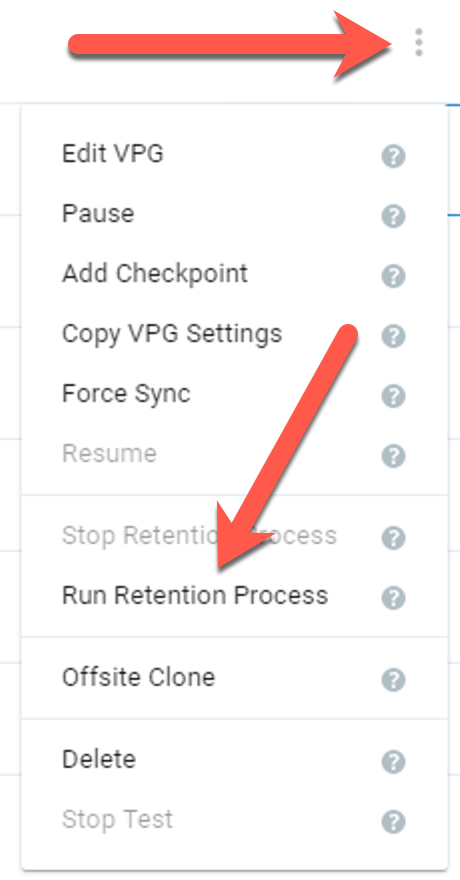
Monitoring LTR to the Backup Store
Now that the retention job is running I wanted to monitor how quickly it was working. My lab is at a colo and I generally see 200-300Mbps of internet throughput when downloading or uploading to various places. So I had an idea of what to expect, but I wanted to see what was actually going to the Backup Store.
Normally I would watch the default gateway and monitor traffic there, but since the secure client runs on linux, I just installed nload and started it up.
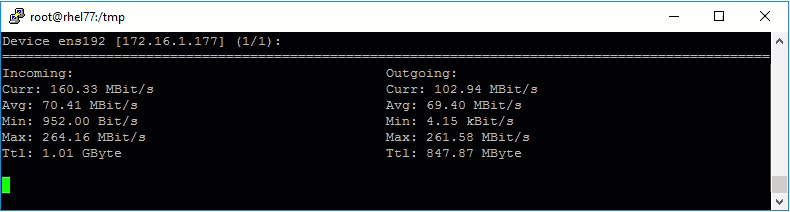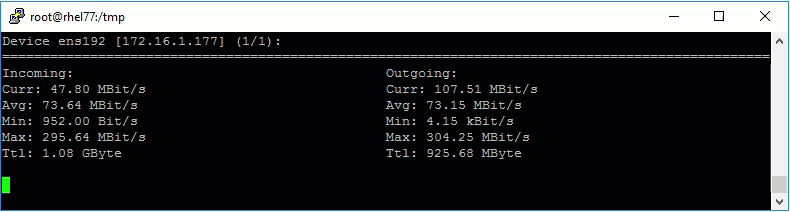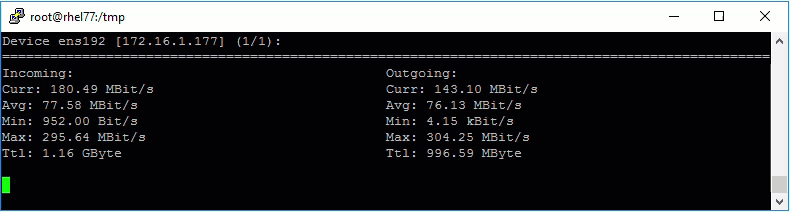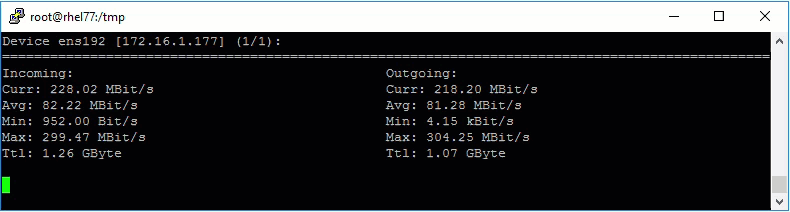
As expected the retention job was able to max out my WAN connection, haha.
Once the retention job was completed I checked the HPE Cloud Volumes site and it was showing an additional 2:1 data reduction on top of the compression that Zerto does to the data.
After a week or two, the ratio is even better. This is because Zerto makes each LTR job (except daily backups) it’s own independent file. You can change this behavior, but by default, it will do weekly/monthly/yearly full backups which can add up fast!
Use cases and conclusions
Zerto’s LTR use cases are limited to VMware and Hyper-V sites, most of which can have a physical StoreOnce device installed without too much trouble. However, more and more customer are looking at services such as Azure VMware Server, Google Cloud VMware Engine, and Oracle’s new VMware offering.
All of these cloud based VMware offerings make it impossible to install a physical StoreOnce device near them. So you have three options.
- Install a StoreOnce VSA inside of the environment (using up costly CPU Memory and Storage resources from the cluster)
- Run a native VSA appliance in the cloud providers “native” VM hypervisor offering
- Send the data to HPE Cloud Volumes
There are many advantages of using the Cloud Volume service, probably the biggest being that its independent of your cloud provider, if you choose to move from Azure to Google, or whatever… its one less thing you have to move.
You also gain a copy of your data in a different region, controlled by a different company.
There is a downside though, egress bandwidth. I’ve been told that the Cloud Volumes service is physically housed at Equinix datacenters right now. So, unless HPE works out some sort of reduced pricing for traffic headed to its services, customers will pay full price for any data that leaves the public cloud provided headed for the Cloud Volumes service. I should note that the data is optimized using source-side Catalyst before it hits the WAN… but it can still add up quickly if you are backing up large datasets.
Update: The folks at HPE have some new information for me, and in fact have worked out agreements with the major cloud providers to reduce bandwidth charges. This is awesome news!
Here are their custom rates for egress to the HPE Cloud Volumes service:
- AWS egress to HPE CV = $0.02
- Azure egress to HPE CV = $0.028
- GCP egress to HPE CV = $0.02
Normally egress is between $0.08 and $.15 per GB depending on the cloud provider! So HPE is getting an awesome rate!
A note on how Catalyst works
A further advantage of using Catalyst to move the data is that dedupe happens on the source-side. This means more work for the Zerto VRAs, but it means huge bandwidth savings in addition to that lower price tag for egress.
For example, lets assume you have a 10TB full backup. The first full backup will cost you about $102.40 (assuming a 2:1 data reduction rate) to get it to HPE. Subsequent full backups that have a 10% change rate would only cost about $10 to transfer offsite.
If you were to send all 10TB offsite with no data reduction (say a storage vmotion)… you are looking at almost $922 in egress bandwidth charges!
Final thought
Overall the HPE Cloud Volumes Backup service looks promising, you get all the awesomeness of HPE’s StoreOnce device without the need to purchase and install hardware. If HPE can negotiate some reduced traffic pricing with the major cloud providers then I see no downside to leveraging this service for on-prem as well as cloud-based environments. (I just worry about egress bandwidth costs if there isn’t a reduced rate.)
Cloud Volumes Backup is just one of the services HPE is offering, I hope to check out how it works as Kubernetes storage next! Stay Tuned!
![]()



