After posting my two Zerto Swap Disk articles for Linux and Windows I received a comment asking why wouldn’t I just reserve all the VM’s RAM which would eliminate the VMware swap file and replication of swap data. This seems to be a pretty common misconception as I’ve run into this on a call with a reseller as well.
Simply put, a virtual machine has two places that swap files exist.
- VMware ESX creates a swap file (assuming that 100% of the VM’s RAM isn’t reserved). It is placed in the datastore alongside your VMX file and VMDK files.
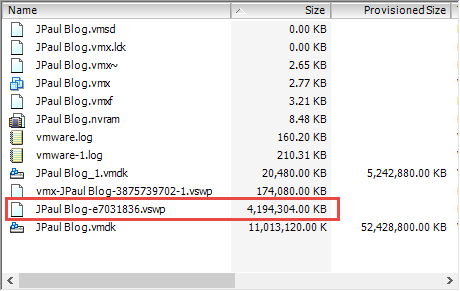
Here in the directory for my blog’s VM, you can see that there is a 4GB .vswp file because I have allocated 4GB of RAM from VMware to my Ubuntu VM - The operating system also creates a swap file as well. (because remember it doesn’t know its virtualized)
Here you can see where the swap is stored – the partition that we added in my linux zerto swap article

output of available swap spaces inside of Ubuntu VM And here you can see the system actually using it
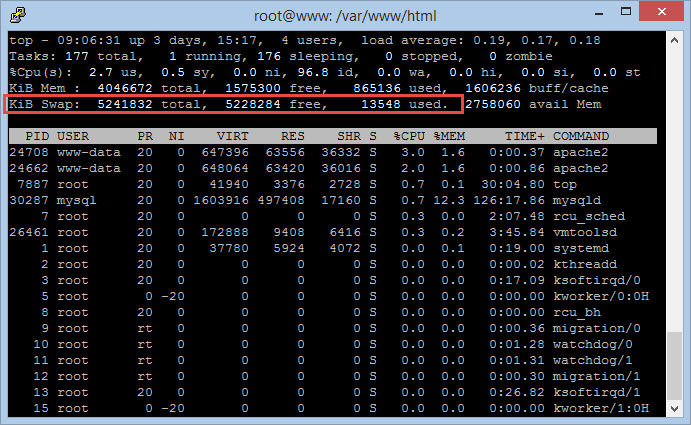
‘top’ utility showing my blogs usage of its swap partition
So if you reserve all of your VM’s memory you will eliminate the first swap location (the VMware .vswp file), however you will not eliminate the swap inside of the guest operating system. The reason for this is because operating system’s (for the most part) don’t really know they are virtualized. So in assuming that it is not, it (the guest operating system) must account for memory usage above the physical amount of RAM it has (remember it thinks it is on real hardware).
Most hyper-visors these days also allow you to over allocate physical RAM, meaning that you can assign more virtual RAM to VM’s than the amount of physical RAM actually in the host. So just like any other operating system, there has to be a mechanism in place to handle the memory pages in excess of the physical RAM. This is the reason that VMware creates .vswap files.
Zerto, by default, will not replicate a VMware .vswp file…EVER. So in my previous articles that is why I didn’t talk about them.
Zerto only replicates two things: vDisk 1’s + 0’s and metadata.
This is very important to remember, because of this Zerto is super flexible. Binary data (1’s and 0’s) are the same no matter what platform you are on (HyperV, VMware, KVM, Azure, AWS, etc), and metadata can be easily translated to whatever platform you want. This means to Zerto metadata is more useful than say a .vmx config file because when I want to convert a VMware VM to HyperV all I need to do is ask the hyper-visor for a VM with the metadata as the source VM.
For example if I said, “Hey Mr HyperV API, I need a new VM it needs to have 2vCPU, 4GB of ram, and a network adapter on this switch, please create that.Oh and by the way, attach this VHDX file I already created to that new VM”. HyperV would happily create the VM. However if I said “Hey Mr HyperV server please import this .vmx file”, I would receive an error similar to the middle finger.
So by having the vDisk 1’s and 0’s along with the metadata about a VM, Zerto can take your data anywhere you want to go… provided we have written the API integration into the platform.
As always if you have any questions let me know.
![]()




Pingback: How To Use Zerto's Swap Disk Feature with Windows - Justin's IT Blog | Justin's IT Blog
Pingback: How To Use Zerto's Swap Disk Feature with Linux - Justin's IT Blog | Justin's IT Blog