I remember back to when I was a kid, probably 12 years old, going into the mill with dad or grandpa and instantly heading towards the DTN terminal. It was a computer that got data from space, and it showed the weather, it was basically the coolest thing ever. What I didn’t care about back then was corn and soybeans market data… little did I know that 25 years later I would care!
Farming has been part of my life forever, and until this year I’ll be honest — I didn’t really have the ability to accurately and consistently track grain pricing around me. A spot-check on one elevator’s website on a morning when I was thinking about selling. Maybe a phone call. Maybe nothing for weeks at a time when I was busy. No history I could go back and look at. No way to compare the local elevators against each other and against CBOT side-by-side. Definitely no way to know whether today’s basis was tighter than last weeks, because I hadn’t written last week’s down.
Big famers don’t run like that. They’ve got a marketing advisor on retainer who pings them when basis tightens, when futures break a level, when a local processor is short and willing to pay up. That advisor is expensive — easily five figures a year in fees and percentages — and they’re not going to take a small farmer like me as a client even if I could swing the bill.
So I built my own. Not as fancy, not as connected, but something that actually knows what every elevator within reach is paying today, has the full history sitting in a database, and — this is the part that genuinely surprised me — can be asked questions in plain English by me or an AI advisor when I’m planning out the season.
The whole thing runs on a Linux box in my homelab. Costs me effectively nothing per month. From the first commit to a working dashboard that was actually scraping live cash bids took less than 8 hours of vibe coding with Claude — the latest Opus model genuinely thinks through a multi-vendor scraping problem lightning fast. Everything since then has been incremental: a new chart here, a new scraper there, the MCP server a few days after I had enough data to want to ask it questions. Here’s the tour.
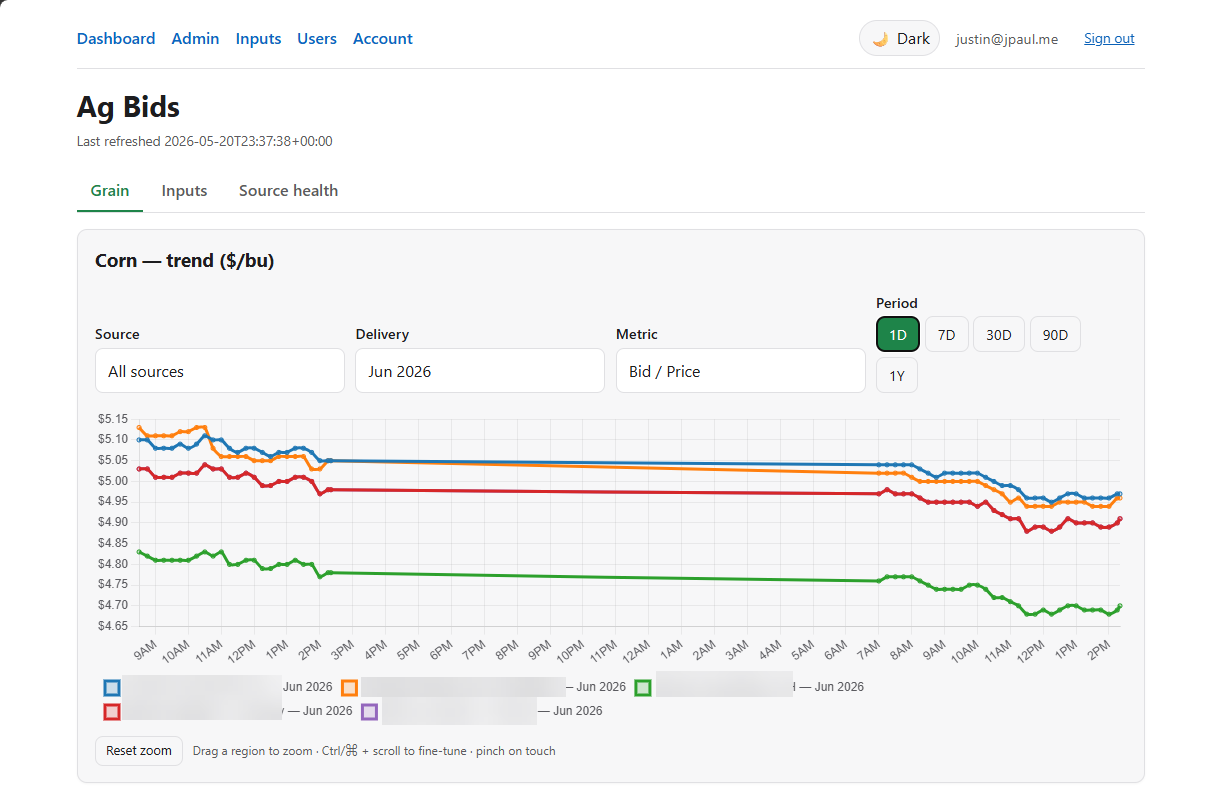
What it actually does
At its core, ag-bids is a small Python service that does three things.
It scrapes the public cash-bid pages of the local elevators around me, every 15 minutes during the CBOT day session, Monday through Friday. It stores every quote in a SQLite database — full history, so I can chart basis trends and look back at what last May looked like. And it presents the latest snapshot on a self-hosted dashboard with charts I can click-and-drag to zoom into, plus an email twice a day that summarizes the market in four or five sentences.
There’s a CBOT futures pull too, because basis only makes sense when you’ve got the nearby futures contract to anchor against. Corn, soybean, and wheat continuous futures, hourly, via Yahoo’s grain tickers.
The dashboard tells me, at any moment: who has the best cash bid for corn delivered this month, the same for beans, how that basis compares to last week, which scrapers are stale (in case something broke), and lately a price-trend chart per commodity that I can drag a rectangle on to zoom into any past window.
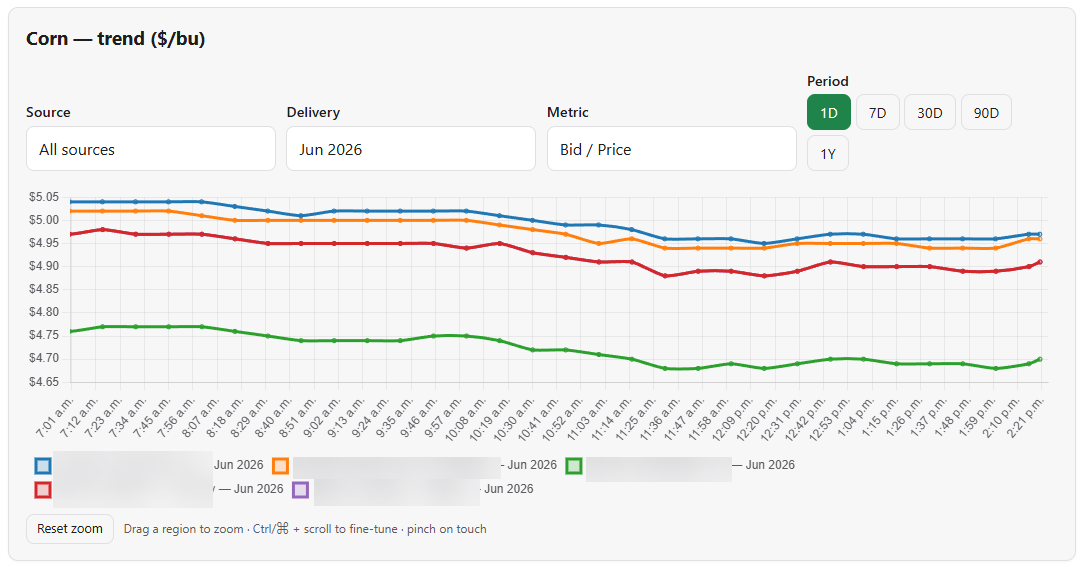
The data plumbing nobody warned me about
Without AI this project would have stalled on the first day. Each elevator’s bid page is its own little universe, and solving each one would have been a multi-day, beat my head against the wall, session. However, with frontier AI models like Opus 4.7, I was able to knock out all targets in a single afternoon.
Two of the elevators around me serve their bids as plain HTML you can parse with basic Python. Great. The next four — every single one — load their data client-side from a different third-party widget vendor.
One uses a DTN feed gated behind a session cookie and an anti-forgery
token. Another uses a Barchart-hosted endpoint that returns JavaScript
wrapped around a var bids = [...] blob. Another is on a platform called
Bushel. Another is on a CIH endpoint that, on top of all that, returns
its bids as a JSON-encoded HTML string. (Three different vendors, three
different “how do you authenticate”, three different ways to extract a
price. I learned more about how the grain industry’s quote software
actually works than I ever wanted to.)
If I’d been doing this by hand, I’d have given up on at least two of them. What changed is Claude. I’d hand it a saved copy of a vendor’s page, say “figure out where the bids actually live, then write me a scraper,” and the Opus model would chew through the minified JavaScript and the wrapped JSON and come back with a working parser in minutes. Each vendor went from “unknown unknowns” to “tested, working scraper” inside an hour.
The grunt work that used to make web scraping a chore — reading minified JavaScript, hunting for the right AJAX endpoint, decoding the fractional cents-per-bushel notation that grain futures use — is something I mostly delegate now. Each scraper ends up with its own unit test built around a saved fixture of the vendor’s response. If they redesign their widget, I’ll see a red test before I see a broken brief.
Cleaning the data so it actually compares
Every elevator’s display labels are slightly different. One uses “May 26.” Another uses “May 2026.” Another uses “June/July 2026.” The CBOT side emits “Jul 2026” via the futures contract code. None of those compared cleanly in a database query — they were three different rows of “the same thing.”
I built a small normalizer that runs at insert time and rewrites every
delivery label into one canonical form — Mon YYYY for single months and
Mon/Mon YYYY for ranges. A one-shot migration cleaned up the historical
data the first time it booted. After that, “best bid for May 2026
delivery” actually returns one number instead of three spellings of the
same thing. (Took me until I’d been running for two weeks to notice that
the dashboard’s “best of” column was wrong because of label drift. Either
way, fixed now.)
Same story for prices. CBOT grain futures are quoted in cents per bushel
on Yahoo. Elevators publish dollars per bushel. Everything goes into the
database as integer cents per bushel so basis math (bid_cents -
futures_cents) is just integer subtraction. There were a fun couple of
days where my “best corn bid” was showing $480.00 instead of $4.80.
The intelligence layer
Once the data is clean, the interesting questions become easy to answer.
“Where’s the best place to sell corn today?” is the first one I wanted answered, and it’s surprisingly subtle. It only counts if the elevator is posting a bid for this calendar month’s delivery — selling corn for December delivery is a different decision than hauling a load tomorrow. So the code filters local bids to the current month, finds the highest, and surfaces the source name, the bid, and the basis. CBOT is explicitly excluded from this because CBOT is an exchange, not a place I can drive a grain cart to.
“What’s basis doing?” gets answered by a chart filtered to one delivery month at a time. Watching basis is how marketing advisors earn their fees — the difference between “futures going up but my local price isn’t” (basis weakening, an elevator signal that nobody wants more bushels right now) and “futures flat but my local price climbing” (basis strengthening, an elevator signal they need bushels).
“Just send me an email twice a day.” Two cron jobs on the same host that runs my farm-news brief produce a market summary at 10:30 AM ET (about an hour after CBOT opens) and again at 3:00 PM ET (about 40 minutes after settle). Both are BCC’d to everyone who’s opted in on the dashboard’s account page, so my dad and a neighbor can be on the list without anyone seeing each other’s addresses.
A typical closing brief in my inbox now reads like this:
Corn ZC=F last $4.6600 (-0.0900).
Best for today's delivery (May 2026): [local elevator] @ $4.9500
(basis $0.3000).
Soybeans ZS=F last $11.9900 (-0.1100).
Best for today's delivery (May 2026): [local elevator] @ $11.9000
(basis $-0.0800).
Two paragraphs, real numbers, no fluff. (The actual elevator name is in the email of course — I’m just being polite by leaving it generic here.)
For the narrative paragraph at the top of the email, I let a local language model take a swing at writing a 4–6 sentence human summary. The LLM runs on the same network as the rest of this — no API costs.
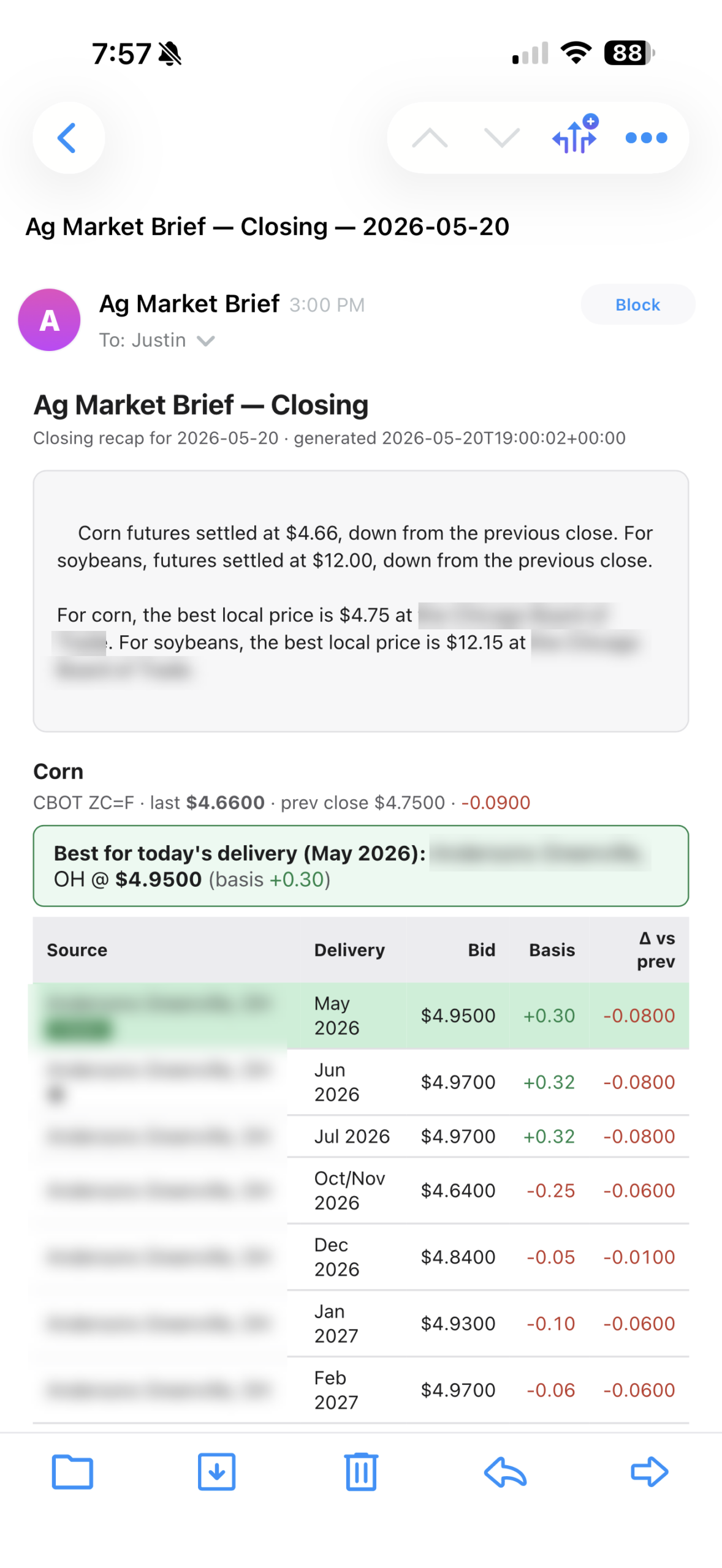
Things that already broke
Worth showing the failures honestly. The initial build was fast, sure, but every “I built X with AI” post I read seems to skip the part where the AI confidently produced something completely wrong. Mine did plenty of that, and the failures keep showing up incrementally as I add features.
The biggest pothole was the LLM happily hallucinating. One afternoon my closing brief read “the best local price for corn is $4.75 at the Chicago Board of Trade.” Two errors in one sentence. CBOT isn’t a local elevator. And $4.75 wasn’t a real number — the model just made it up.
I tried tightening the prompt. The next afternoon the LLM wrote “best bid for corn is $11.90 from Elevator [X]” — wrong elevator, and that price was actually soybean’s, not corn’s. The model was mixing up rows in the table.
So now the analyzer runs every Ollama response through two guardrails before it ever hits an email. One checks whether the narrative mentions CBOT in proximity to “best / haul / sell” language. The other checks whether the narrative actually names the elevator the data picked as today’s best. If either fires, the brief falls back to a deterministic template that can only reference real data. So the AI gets a try, but never gets to make something up.
Other things I had to fix along the way: a scheduler container running
stale code because I forgot to rebuild it after refactoring (charts
showed up with no lines between data points until I caught it); a
checkbox on the account page that rendered as a giant text input because
my CSS was over-aggressive with appearance: none; an entire afternoon
spent finding out CBOT actually trades 24/5 with a 45-minute daily pause,
not the 9:30 AM – 2:20 PM ET “day session” I’d assumed when I picked the
scrape window.
Each one was a 10-minute fix once I knew what was wrong, and an evening of head-scratching to figure out what was wrong.
Then the crop advisor chat happened
This is where the project started feeling like more than a hobby.
Most of my crop planning — fertilizer rates, what to plant where, how much to sell at harvest versus hold versus contract forward — used to happen in my head or best case a spreadsheet. Earlier this year I started keeping a dedicated Claude chat that I treat like a crop advisor: I describe what’s going on, paste in soil tests, ask “given these prices what’s a reasonable basis level to commit to a forward contract at?” It’s been genuinely useful. The thing it could not do was know the actual current price at my actual local elevators.
So I wired the dashboard to an MCP server.
MCP — Model Context Protocol — is a recent open standard for letting AI clients call structured tools on external servers. When you set up an MCP server with a list of tools (each one a Python function that returns a markdown string), any compatible AI client can list those tools, discover what they do, and call them with arguments. The AI decides when to call a tool based on the conversation. The user doesn’t have to ask “use the ag-bids tool” — it just figures it out.
I run a single MetaMCP gateway in my homelab that fronts multiple MCP
servers — one for Zerto docs (which I wrote about earlier), one for
ag-bids, room for more — under a public hostname. When my Claude advisor
chat needs live prices, it doesn’t need to know how to query a SQLite
database or talk to ten different elevator widgets. It just calls
best_local_bid(corn) and the MCP server returns:
### Best place to sell corn today (2026-05-20)
**[Local elevator]** — delivery **May 2026** — bid **$4.9500/bu**
(basis +0.30, futures ZCN26)
_Fetched 2026-05-20T15:30:00+00:00_
It can also call current_lime_price() to get my latest manually-entered
lime quotes (lime usually only comes from phone calls — I just type it
into the dashboard), or price_history(corn, days=30) to chart the
trend when I’m thinking about locking in basis ahead of harvest.
I’m not going to share specifics of the chats themselves — those are candid conversations about my farm — but as a category, the questions the advisor can now answer with live data instead of guesswork include:
- Given current basis levels and futures, does it make sense to forward-contract any corn for fall delivery now, or wait?
- Today’s fertilizer prices versus historical seasonal patterns — when in the year is it usually cheapest to lock in?
- If futures stay flat and basis tightens five cents over the next two weeks, what does that imply for the marketing plan?
The advisor doesn’t make the decision. I do. But for the first time I’m having that conversation with somebody — even if “somebody” is a language model — that can see the same prices I’m looking at, in real time, while we’re talking.
What this actually changes
I keep coming back to why this was possible now and wasn’t before.
The technical pieces aren’t new. Web scraping has been around since the 90s. SQLite is older than my high-school diploma. Grain futures have always been API-fetchable for the cost of a Bloomberg terminal or a tiny bit of public Yahoo data. Cash-bid widgets have been on co-op websites for at least a decade. The intelligence to overlay those things and ask “where should I sell?” has existed since the first marketing advisor opened shop.
What was missing for somebody at my scale was the labor cost of gluing it all together. Reverse-engineering six different bid-feed vendors, writing the per-vendor parsers, designing a normalizer that turns six flavors of delivery labels into one, making the email render look decent in dark mode on a phone, getting an MCP server wired up behind a gateway — all of that is real work, and the labor cost would have eaten any savings from the better marketing decisions it enables.
AI didn’t write this entire system. I designed it. I made every call. I tested it, deployed it, fixed it when it broke (see the section above where it broke). But every step where I would historically have stalled out — that vendor’s javascript is opaque, that fractional-cents notation is unfamiliar, that streamable-HTTP transport isn’t documented — I now have a coding assistant that can help me get unblocked in minutes instead of weeks.
What that means in practical terms: a small farmer can now afford to build the kind of tool that used to require a five-figure advisor contract. Not because the labor is free — it isn’t — but because the labor multiplier is high enough to bring projects that used to be uneconomic into reach.
I’m not the only person this is going to be true for. The same shift is going to play out in every domain where the data is public-ish, the intelligence layer requires real expertise to design, and the labor cost of the gluing-it-together middle has historically priced out everyone but the big operations.
What’s next
Stuff on the list:
- More inputs. Fertilizer prices (MAP, potash) come from a weekly DTN national-average article right now. Lime is still phone-entered. I want a regional fertilizer source if I can find one.
- A proper PWA on the dashboard. I want to glance at the best bid from my phone on the way to the elevator without logging in.
- More MCP tools. The obvious ones are written. As the crop-advisor chats deepen I keep finding questions that would be better served by a purpose-built tool than by asking the model to reason from raw history rows.
- Tying it to the smart ag sensors. Long-time readers know I’ve been working on a Raspberry Pi Pico-based fertilizer flow monitor too. Eventually the two systems are going to meet — what I’m applying on which acres, alongside what I’m getting paid for what comes off them.
Part 2 will probably dig deeper into one of those threads. Until then — if you’re another small-acreage farmer who’s been frustrated by the gap between what big operations get from their advisors and what’s available at your scale, I’d love to compare notes. And if you’re a developer who’s been on the fence about whether your domain has room for an AI-assisted side project: it almost certainly does. The friction is lower than you think.
Stay tuned for updates!
Happy to answer questions in the comments.
![]()



